短网址系统可能是最常见的分布式系统设计问题之一了,本身从业务需求上说,读远多过写,而且数据结构确定且简单,数据量小,还易于使用缓存,因此本身难度在分布式系统的问题里面算是比较低的。另外,这个系统本身 “分布式” 的特性也比较弱,而且从组件图的角度来说,没有多少是 “可画的” ,因此之前也就没有介绍它。不过后来我改变想法了,我觉得还是可以总结总结,特别是可以把一些相关的特殊需求考虑进去。
短网址服务就像是 bit.ly 这样的,给一个长长的 URL,它给你吐出一个较短的 URL,往后访问这个 URL 就可以做到 302 重定向到原来那个长 URL 了。
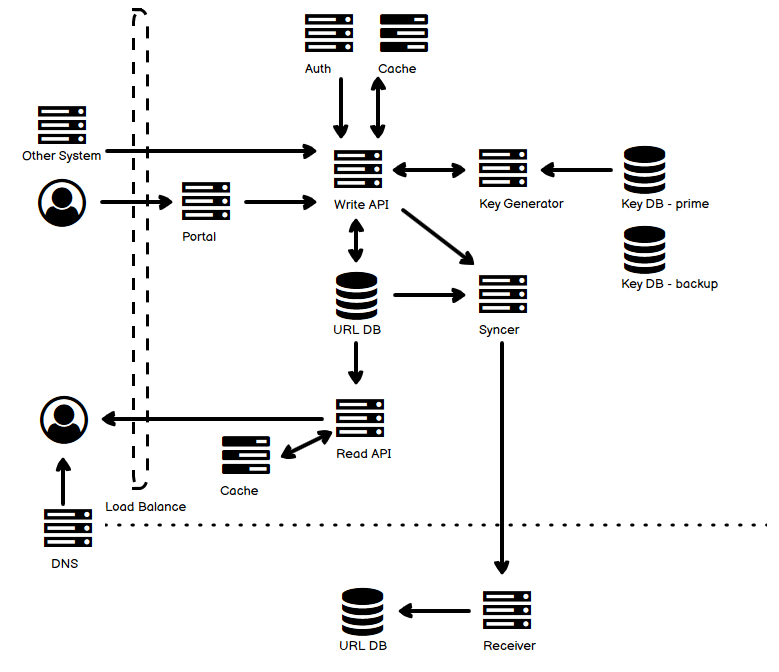
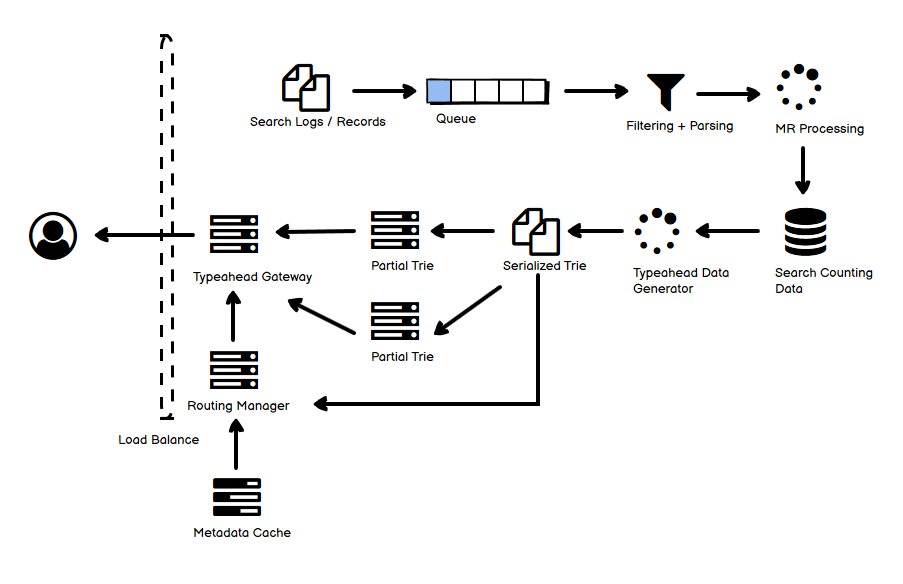
- 图中上半部分是写的部分,无论是 API 直接调用还是
[……]阅读全文
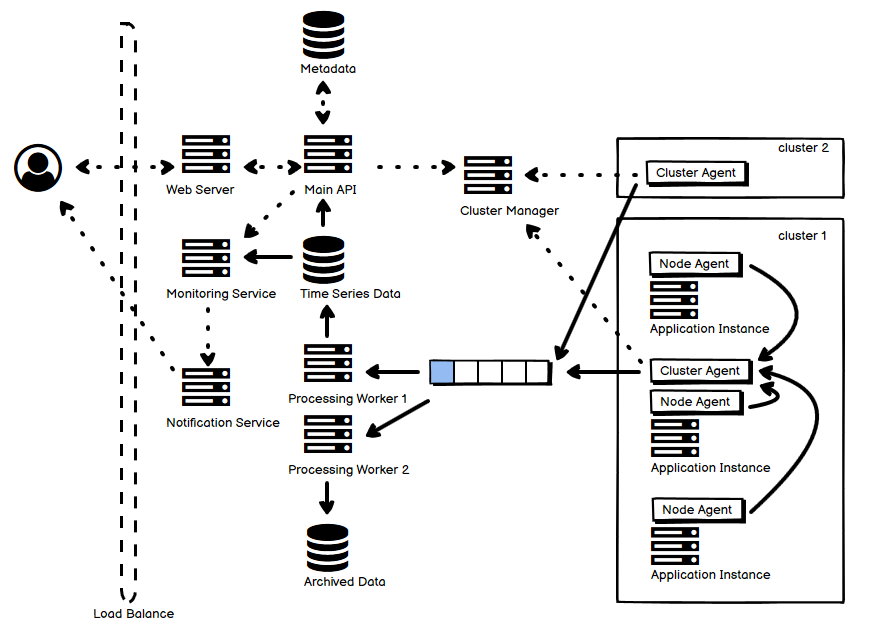
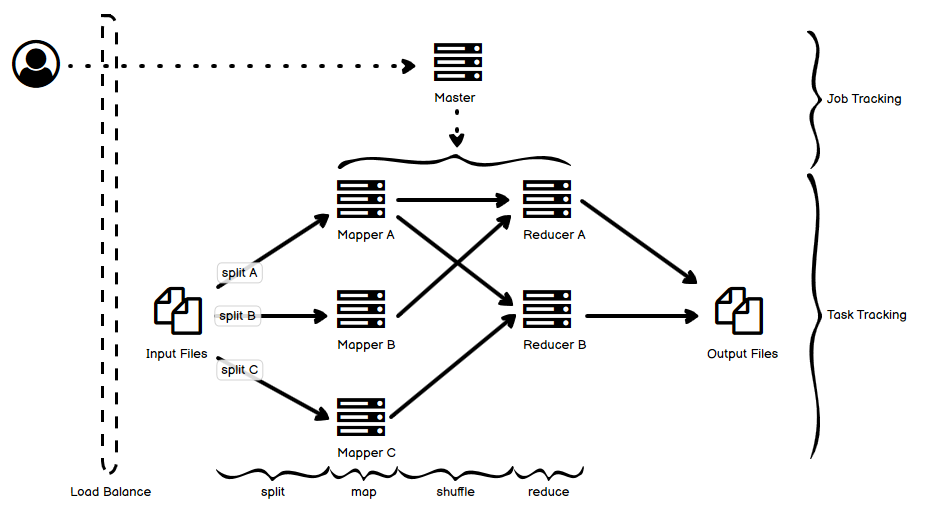
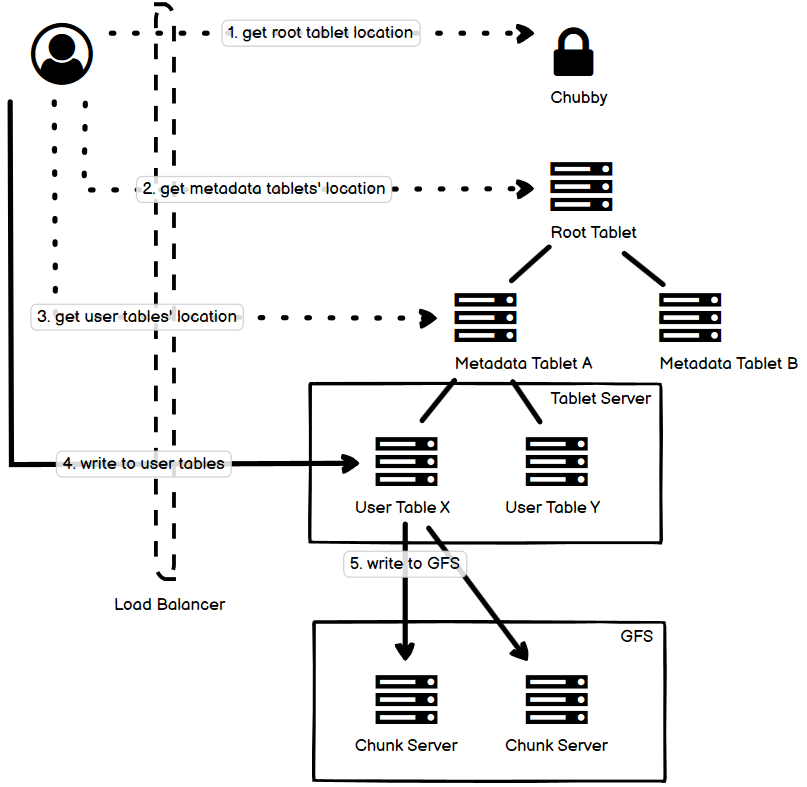
 如同我在第一篇文中说的那样,自己在学习各种各样分布式系统的过程中,做了一些笔记,也有自己的理解,把它们放到一起,用一张图选择最主要的部分来阐释,从我的角度来说,是能够帮助理解和记忆的。事实上,遇到的很多各种各样的分布式系统,绝大多数都逃不出那最常见的十几种,也就是说,逃不出这些 “套路” 和 “玩法”。这就是把它们整理成一
如同我在第一篇文中说的那样,自己在学习各种各样分布式系统的过程中,做了一些笔记,也有自己的理解,把它们放到一起,用一张图选择最主要的部分来阐释,从我的角度来说,是能够帮助理解和记忆的。事实上,遇到的很多各种各样的分布式系统,绝大多数都逃不出那最常见的十几种,也就是说,逃不出这些 “套路” 和 “玩法”。这就是把它们整理成一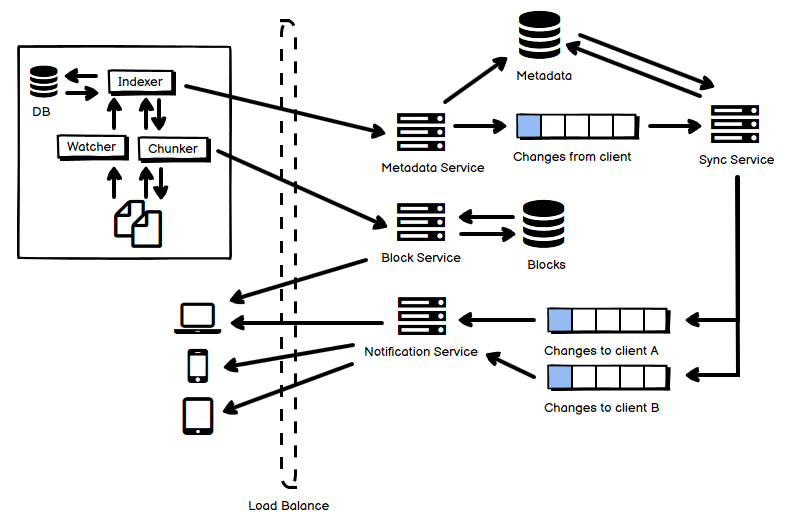
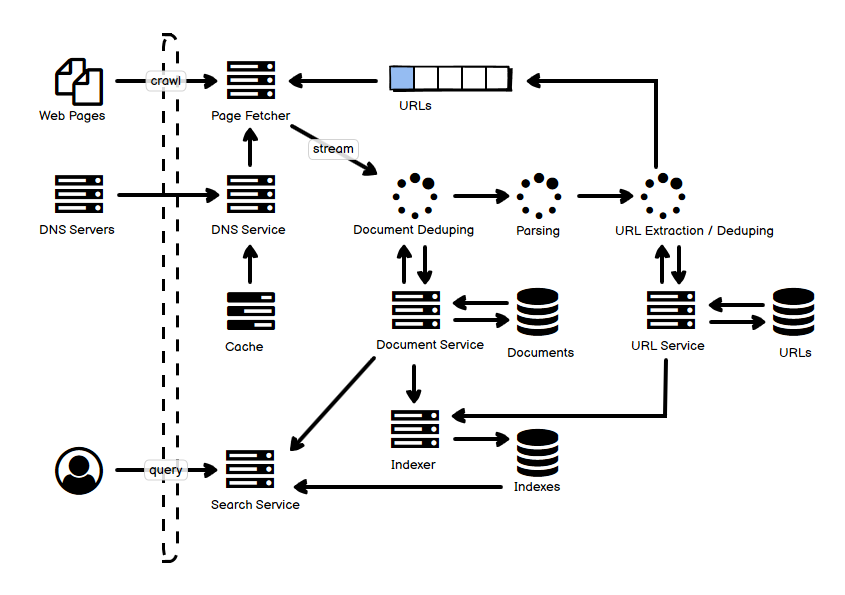
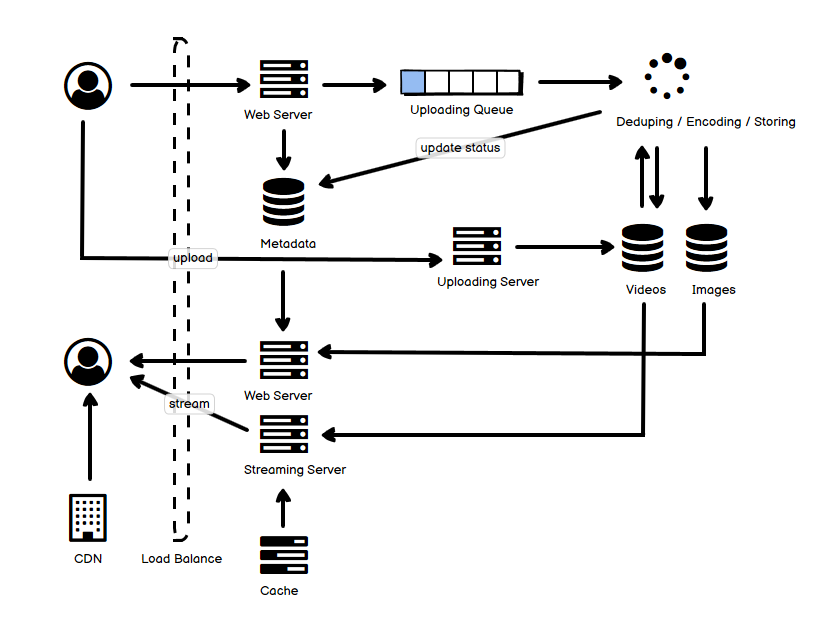
 拿到一堆数据,去做架构也好,设计也好,可行性分析也好,工程上需要的是严谨。但是也有很多场景,比如即时的问题争辩和讨论,我们往往需要的是快速、直接的估算,这样的数据显然不需要非常精确,甚至可以说它一定会非常粗略,我们的目标往往只停留在 “量级” 的级别,但是我们依然可以对方案有一个具体的、量化的认知,这比像 “海量”、“高吞吐”、“低延迟” 这类感性的、描述性的表述还是要清晰和有力得多。
拿到一堆数据,去做架构也好,设计也好,可行性分析也好,工程上需要的是严谨。但是也有很多场景,比如即时的问题争辩和讨论,我们往往需要的是快速、直接的估算,这样的数据显然不需要非常精确,甚至可以说它一定会非常粗略,我们的目标往往只停留在 “量级” 的级别,但是我们依然可以对方案有一个具体的、量化的认知,这比像 “海量”、“高吞吐”、“低延迟” 这类感性的、描述性的表述还是要清晰和有力得多。