互联网搜索引擎都有爬虫系统,无论是 Google 还是百度。当然这里我们讨论的只是一个极其简单的版本。
对于爬到的资源,我们这里其实讨论的只是文本而已,还有图片、音频、视频这些媒体,如果我们也需要存下来,那就需要专门的媒体服务。对于媒体文件的存放,在之前的文中已经讨论过,这里就不再覆盖了。
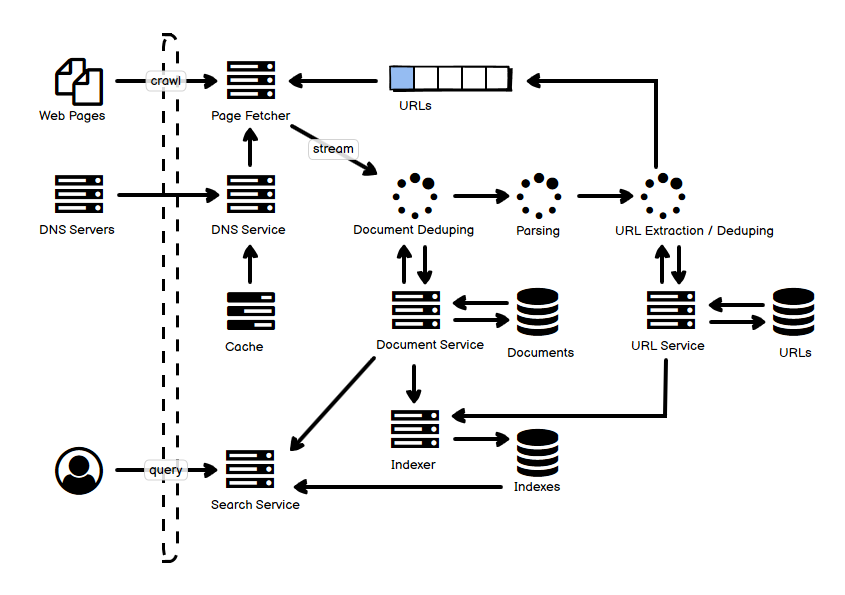
- 上半部分是爬取的过程,Page Fetcher 根据 URL 队列里面的事件来去实际的页面中爬取内容。不同的网站可以使用不同的 queue,配合从不同 queue 中 poll 的策略,这样可以合理分配资源,避免对某一个网站投入了太多的资源。爬虫需要解析 robot.txt,也要限制爬取的进程/线程数,保证不会有太多的爬虫访问冲垮网站。
- DNS Service 其实是一个统一存储域名到 IP 解析服务的组件,这个组件可以缓存下一些 DNS 的查询结果,因为如果单纯地在每次爬取过程中依赖于互联网 DNS 查询,请求量会过大,而且具备大量的重复请求。
- Dedup(去重)是一个重要的步骤,既包括文档的重复识别,也包括 URL 的重复识别,可以使用一个简单的 checksum 来实现,对于新的网页文本和 URL,分别存到各自的数据库里面。
- 网页的数据库可以使用 Bigtable 这样适合存放小型文本的存储服务,URL 则可以存放到 KV 数据库中。为了提高查询和比较的效率,checksum 可以缓存在内存中。
- 对于网页上新(未爬取)的 URL,放到队列中,以便爬虫工作。
- 下半部分包括了索引的建立,即从查询词到文本内容的索引。也包括了搜索这个行为——Search Service 处理查询语句,查询索引数据,进行过滤和排序,并返回结果,而页面镜像可以从 Document Service 处获取。
这是《常见分布式系统设计图解》系列文章中的一篇,如果你感兴趣,请参阅汇总(目录)寻找你其它感兴趣的内容。
文章未经特殊标明皆为本人原创,未经许可不得用于任何商业用途,转载请保持完整性并注明来源链接 《四火的唠叨》
请教下,这里 URL Service 到 Indexer 要表达的是什么逻辑呢?
我这才看到这条没有回复。Indexer就是用来做从关键词到文档的反向索引,它的形式可以是这样:
keyword -> List(docId:position)
也可以不使用docId,而是使用urlId
keyword -> List(urlId:position)
这就是那个 URL 指向到这里的箭头的原因