“ Top K 系统 ” 是非常常见的一种子系统,基本上,就是从全量巨大的统计数据中,筛选出数值最大的 K 个来并按序展示。这样的筛选可以是全时间内的,也可以是最近某一段时间内的;可以是全分类的,也可以是某个特定分类的。
具体来说,像 Twitter 的 Trending Topic,微博热搜,视频网站的点击排行,下载排行(可以是日榜、月榜、总榜)等等。这样的系统,在统计数据非常大(heavy hitters)的时候,其中的挑战性在于两个:
- 无法简单地在单台机器的内存中进行目标 id -> count 计数的简单映射,因为数据量太大,内存放不下。
- 无法用实时的方式高效地显示出动态变化的 Top K 列表来。
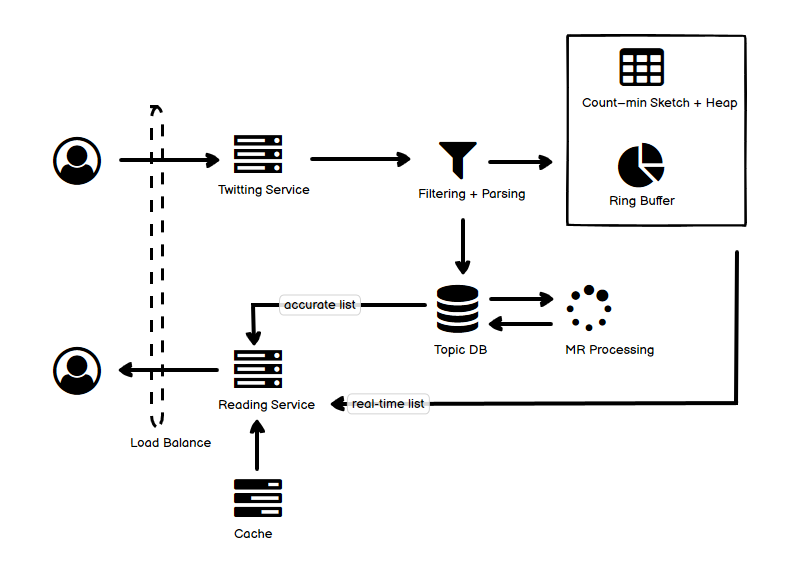
- 上图包含了两个思路,一个是实时排行(榜单),通过 Count-min Sketch 实现,快速,但是不够精确(或者使用 Lossy Counting);另一个是周期性排行,通过异步的 MR 数据处理实现,数据上看比较准确,但是处理是异步的,实时性差。
- 第一个思路方面,统计要尽可能实时。为了提高处理效率,用户的话题引用可以直接进入 filter 进行处理。在我读到的某些材料中,类似系统这一步也有通过异步批量的方式进入队列并处理的。不过在这里,我还是保留了比较简单的一种实现。
- 接着经过简单的 filtering 和 parsing 去掉不关心的数据,比如对于微博的话题来说,某一些词是小词,或者是我们不希望成为话题的词;而某一些近似词可以合并。完成以后数据有两个去向,一个是右侧的即时统计,一个是持久化到下方的数据库中(这个数据库可以是 Redis 这样的 KV 数据库)。
- 对于每一个词,经过 hash 以后,到 Count-min Sketch 表格中累积计数,并根据计数到当前大小为 K 的最小堆(这个最小堆用来存放一定时间内累计的前 K 大条目)中寻找是否比堆顶更大,如果是,就入堆并移除原堆顶,从而保持堆的大小为 K。由于 Count-min Sketch 这个堆的大小都是确定并可控的,这样的统计就可以在单个节点上完成了。
- 如果需要的即时统计数据不是 “总榜”,而是最近一段时间的 “趋势榜”,那就可以借助 Ring Buffer——比如我们只关心最近一小时的趋势,就可以把一小时划分为 ring 上的 60 个区间,每个区间使用 Count-min Sketch 甚至简单的 Map 分别统计,趋势榜每次可聚合这 60 个区间得出 top K;每过一分钟都覆写最老的那一个区间的数据,从而保证 ring 上的数据始终是最近一小时的。
- 第二个思路方面,统计不实时,但相对精确。对于这些持久化的数据,由 MR 的 job 定期执行来处理,并更新结果到数据库中。
- 读取数据的时候,根据需要可以读取即时统计或者异步计算得到的统计数据,数据可以在外部缓存。
这是《常见分布式系统设计图解》系列文章中的一篇,如果你感兴趣,请参阅汇总(目录)寻找你其它感兴趣的内容。
文章未经特殊标明皆为本人原创,未经许可不得用于任何商业用途,转载请保持完整性并注明来源链接 《四火的唠叨》
count-min sketch 第一次听说,感觉行为有点不可思议。