今天记录 Feed 流系统的设计学习笔记,Feed 流常见系统包括 Twitter、微博、Instagram 和抖音等等,它们的特点是,每个用户都是内容创作者,每个用户也都是内容消费者,每个用户看到的内容都是不同的,它取决于用户所关注的用户列表,再结合时间线(有时还包括优先级)将这些用户的最新 feed 聚合,并以流的方式展示出来。
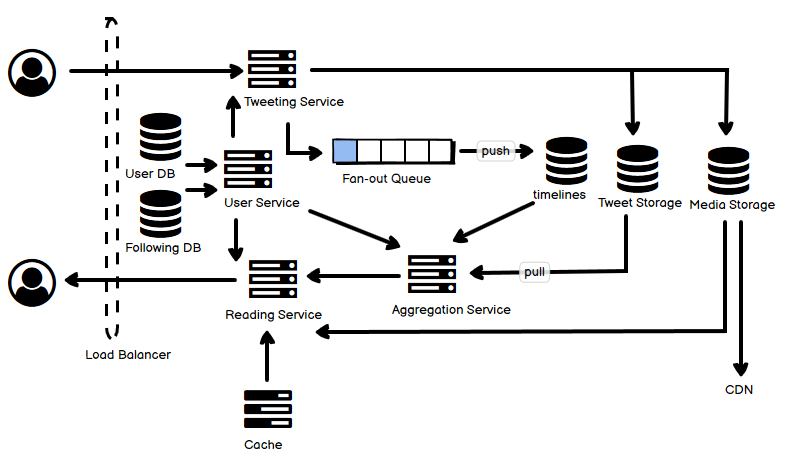
- Feed 流系统中,有两种常见的模式,一种是 push,一种是 pull。基本上,对于用户的 “被关注用户”(粉丝)可能远大于 “关注用户” 的系统,比如 Twitter,pull model 是必选,push 是可选;反之,特别是对于一些用户关系要求必须双向的,比如朋友圈,往往不会有很多的 “粉丝”,那就可以将 push 作为主要模式。无论如何,pull 和 push 有利必有弊,如果结合使用,可以根据场景来选择,看似很美,可又会增加系统的复杂性。这里按照二者结合的设计来叙述。
- 这里提给 push 和 pull 各提一个经典问题:
- 第一个问题是 push 模型下,由于粉丝众多,推文占用容量过大的问题,一种解决思路是在粉丝的时间线中只存储推文 id,但是这样的话在聚合的时候需要一次额外的根据推文 id 去获取推文的 I/O(但是可以通过缓存优化);另一种解决思路是只给活跃用户 push。
- 第二个问题是 pull 模型下,突然某个大 V 的某一话题活了起来,大量的用户访问该推文,导致所在机器顶不住了(这也是新浪微博挂掉的常见原因)。这个也没有太好的解决办法,可以考虑对于特别火爆的推文拉出专门的一层缓存来扛流量,另外要有流控,丢掉部分请求,尽最大能力服务。
- 首先,用户本身的数据,存放在 User DB 里,和很多其它系统一样,它可以是一个关系数据库。但是用户的关联关系,可以单独存放,它可以使用关系数据库,也可以使用 Graph DB。
- 右侧的 Tweet Storage:用户和帖子(推文)的关联数据,数据量会比较大,可以选择 Redis 这样的 KV 数据库;而推文本身,也可以使用 KV 数据库,或者使用 MongoDB 这一类文档数据库,以适应弱结构化文本为主的数据。但是,Twitter 和微博都使用了 MySQL 来存放这类数据,并且 Twitter 给 MySQL 做了相当的优化,这里面不只有技术原因,更多的还有历史原因。
- 关于对推文的 Sharding,这是一个 Feed 系统的核心话题。
- 一种方式是根据时间的范围来划分,这也是 Twitter 早期的做法,这种做法有一个严重的问题,就是老的推文没有人看,而新推文则火得不得了,因此机器的 load 严重不均。
- 第二种方式是根据推文的 id 来做简单 hash,这种方式最大的问题是一个人的推文可能分散到任何一台机器上,为了找这个人的推文要去所有的机器上查询并聚合(既包括网络 I/O,也包括磁盘 I/O),这无疑是过于浪费了。
- 第三种方式是根据用户 id 来做 hash,保证某一个特定用户的推文只存储在同一台机器上,但这个方式有两个问题,(1)有时候某特定几个用户会火,导致 load 不均,这种情况需要用良好设计的 Cache 来缓和;(2)某些用户发推多而某些用户少,因此时间长了 shards 的容量使用差异可能很大,这需要一个改进的找 shard 的路由算法。
- Media Storage,用于存放图像等媒体数据,这可以是一个 “单纯” 的分布式文件系统,比如 HDFS。
- 用户推文的时候,根据用户所应对的策略,如果需要 fan out 推文的 id 到粉丝的时间线数据库中,就要把这个事件进 queue,由于它是异步模型,这一步可能会有不同程度的延迟。
- 在用户读取的时候,缓存是非常重要的,考虑到需要的容量巨大,为了增加命中率,减少冗余的缓存信息,可以使用集中式缓存集群。
- Aggregation Service 是用来从多个存储节点中为某个用户拉取数据(pull 模型),合并时间线,并返回的。为了提高效率,这里是多个并行拉取,再聚合的。这些数据可能是即时拉取的(pull 模型),也可能是已经,或者部分已经在之前的 Fan-out 流程中写入存储而准备好了的(push 模型)。
这是《常见分布式系统设计图解》系列文章中的一篇,如果你感兴趣,请参阅汇总(目录)寻找你其它感兴趣的内容。
文章未经特殊标明皆为本人原创,未经许可不得用于任何商业用途,转载请保持完整性并注明来源链接 《四火的唠叨》
图里 fan out queue 画的位置不是很明白. Aggregation service pull 的时候不应该是从 fan-out queue 里来 pull message 吗?
pull 的时候,有两种数据:
1. 如果是走 push 模型的数据,即经过 fan-out 的数据,这些数据也应该是已经存放在数据库里面了(那个 queue 是待处理的新帖子数据,需要根据该用户的粉丝去生成相应的时间线写到数据库每个粉丝的时间线数据里面去);
2. 如果是走 pull 模型的数据,也就是说没有经过 fan-out 的操作,那么这样的数据是从数据库里面现查并聚合的。
所以不管是 #1 还是 #2,都是去数据库里面查。
不对,用户的 timeline 的生成是通过 aggregation service 是从用户所 subscribe 的人的 DB 里去取数据(包括用户自己),再经过合并后推给用户。但如果对于名人而言也是从他们的 DB 取数据的话,fan-out queue 就没有任何意义了。所以我觉得 fan-out queue 的作用是,直接把名人的数据推到他的粉丝的 aggeregation service 的 queue 里,这样就避免了对名人的 DB 的读操作。
新浪微博挂掉的原因之一是,如果你访问了该名人的页面,那自然就必须读取该名人的 DB,那就不可避免地会挂掉。fan-out 的作用之一就是尽可能避免对名人所对应的 DB 的读操作。
嗯,我觉得你说的是正确的理解。
你说的 “通过 aggregation service 是从用户所 subscribe 的人的 DB 里去取数据” 就是 pull 模型;
那么 fan out,或者说 push 模型在这里是什么?就是要避免对于单点的名人数据过度的读取,因此这个 fan out 就主动把名人的数据分散到其它的 “缓存” 里面,而这个所谓的 “缓存”,可以是一个单独的时间线数据库。
图示已修复