今天聊一下时间的话题。在分布式系统中,“时间” 是一个挺有趣,但是很难处理的东西。我把自己的理解简单整理下来。
今天聊一下时间的话题。在分布式系统中,“时间” 是一个挺有趣,但是很难处理的东西。我把自己的理解简单整理下来。
不可靠的物理时钟
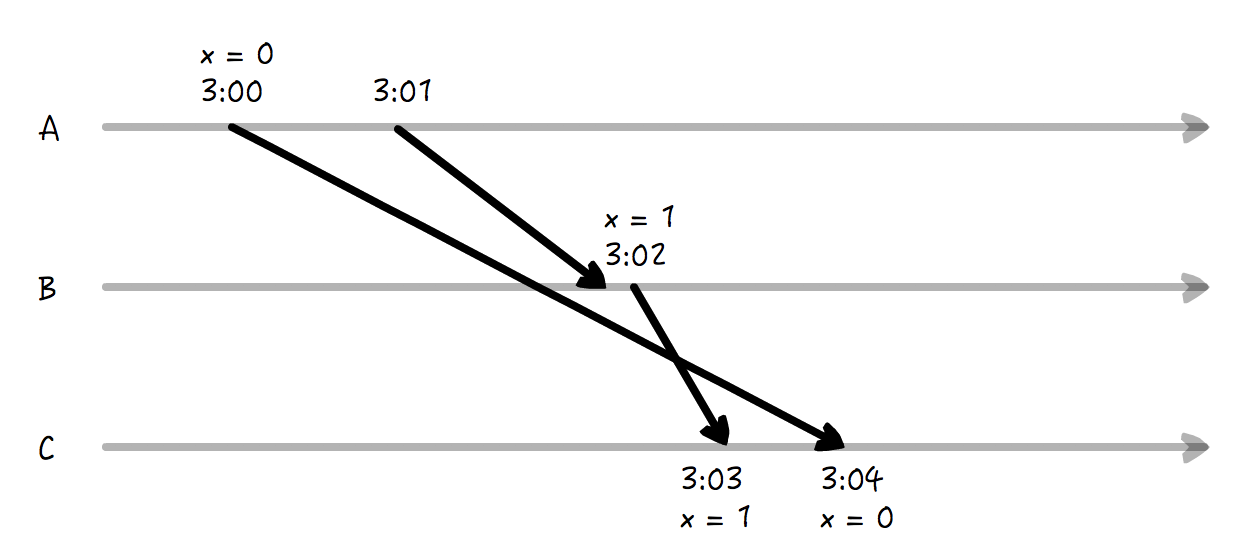
首先,单一节点的物理时钟是不可靠的。
物理时钟本身就有偏差,可是除此之外,可以引起节点物理时钟不准确的原因太多了,比如 clock jump。考虑到 NTP 协议,它基于 UDP 通信,可以从权威的时钟源获取信息,进行自动的时间同步,这就可能会发生 clock jump,它就是说,时钟始终会不断进行同步,而同步回来的时间,是有可能不等于当前时间的,那么系统就会设置当前时间到这个新同步回来的时间。即便没有这个原因,考虑到数据从网络传输的延迟,处理数据的延迟等等,物
[……]阅读全文
 分布式系统有它特有的设计模式,无论意识到还是没有意识到,我们都会接触很多,网上这方面的材料不少,比如
分布式系统有它特有的设计模式,无论意识到还是没有意识到,我们都会接触很多,网上这方面的材料不少,比如 
 就像 Martin Fowler 说的那样,“分布式调用的第一原则就是不要分布式”,谈分布式锁也要先说,不要使用分布式锁。原因很简单,分布式系统是软件系统中复杂的一种形式,而分布式锁是分布式系统中复杂的一种形式,没有必要的复杂性就不要引入。
就像 Martin Fowler 说的那样,“分布式调用的第一原则就是不要分布式”,谈分布式锁也要先说,不要使用分布式锁。原因很简单,分布式系统是软件系统中复杂的一种形式,而分布式锁是分布式系统中复杂的一种形式,没有必要的复杂性就不要引入。