从大致的非功能需求角度来说,作为一般的分布式持久化存储系统,这样三个需求从重要性依次排列:
Durability > Availability > Performance
即最重要的是,数据绝对不能丢失,其次是要一直提供服务,最后才是要保持一定的性能。当然,有了上述基础以后,我们还可以谈论任何分布式存储系统都涉及的重要特性,比如一致性。最后,作为特定的存储系统——“数据库”,我们还常常谈论一些特定的特性,比如权限管理和事务控制等等。
下面拿的是 Bigtable 来举例的,它建立在 GFS 这样的分布式文件系统上面,有一定代表性。
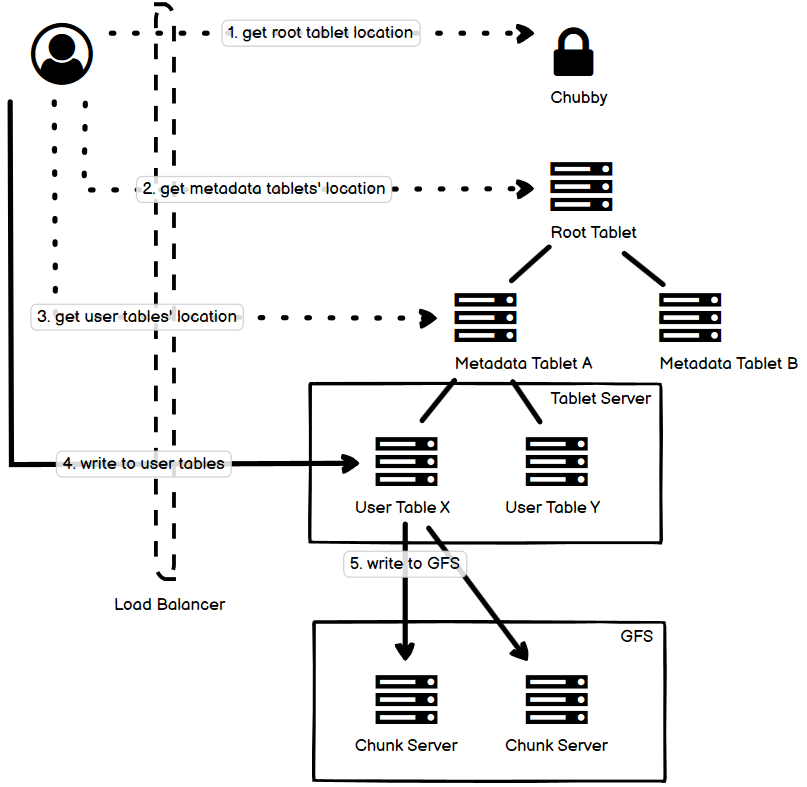
- 图中展示的是一个简单的写数据的流程,虚线是控制流,实线是数据流。
- 客户端先去 Chubby 获取 Root tablet 的地址,然后去 root tablet 获取相应的 metadata tablets 的地址,再去访问 metadata tablet 获取 user tables 的地址。
- 上面的地址都是可以被 cache 的,所以实际的访问多数情况下远不需要那么多。
- 我们在讨论 tablets 的时候,实际讨论的是逻辑层面的东西,而它们实际会被持久化到 SSTables 里面去,在 GFS 上就是一个个的文件,这是物理层面的东西。
- Tablet Server 持有 GFS 的客户端来实现对文件系统的读写。客户端不和 GFS 直接打交道,而 GFS 并不关心 Bigtable 层面的概念,只关心文件 block 的读写。图中我省掉了 GFS 的 Master 结点。
- Bigtable 的数据分成这样几种存放形式:
- 一种是稳定的、有序的数据,sharding 后存放在 SSTable(Sorted String Table),每一个 SSTable 有自己的 index 和 bloom filter,前者用来加快数据定位,后者用来快速存在性判断(尤其是它判断得到不存在的结果的话,它的正确率是 100%)。Tablet Server 的内存中也会有部分 index 和全部 bloom filter 的拷贝,以提高数据定位的效率。
- 第二种是由于数据增加、修改等原因,未和上述一起排序的 “额外” 的数据,这些数据一开始是存放在 Tablet Server 的内存中的,使用一个 Skip List 来维护,它们定期归并到上述的 SSTable 中去。为了防止这些数据丢失,需要使用 WAL(Write Ahead Log)持久化到 GFS 中,这个过程是很快的。这样这些后来的新增和修改操作既保证了效率,又不丢失持久性。
- 由于 GFS 的特性,对数据追加的操作可以高效完成,但是数据修改却往往不是(比如某个值的修改导致其占用的空间增大,原地修改将导致整个文件的数据从该值的位置开始向后平移)。这个限制非常关键,Bigtable 的数据修改一般都是通过内存中的追加写操作来完成(使用一个 Skip List 来维护),内存中的追加操作达到一定大小阈值以后,它们将被磁盘序列化为 SSTable,而它的内部是有序的。于是,一条数据记录可能存在多个版本,在内存(无序)中和多于一个的 SSTable(有序)中都存在,但只有最新的一条才作数。
- 因此对于某条数据的读取,是有可能从多个地方读取的,即 Tablet Server 的内存和多个 SSTable。在查询获取某一 key 的数据的时候,需要先访问内存中的 Skip List;然后对于硬盘中有序的 SSTable,过一遍 Bloom Filter(它可以长期待在内存里以减少磁盘读取),再加载它部分的 index 到内存中,从而定位到数据位置。
- 每隔一定时间,所有这些 SSTable 可以做一次归并整理(有 k 个 SSTable 那就是 k 路归并),顺便剔除过期数据。
Bigtable 的数据模型符合这样的结构:
(row:string, column:string, time:int64) -> string一个 row key,一个 column key,一个时间戳,combine 起来映射到一个 string 上面去。
Row key 是根据字典序排列的,并且因此自动划分范围并 partition。这种设计可以让相同前缀主键的行放在一起,处理起来就可以按照 range 来读取,很高效。事务控制上,Bigtable 也支持基于单行的事务。一个 range 的 rows 就被划分为一个 tablet,tablet 是 Bigtable 做 rebalance 最小的单位。
多个 column keys 可以组成一个 column family,这个概念的实现,基本上除了 Bigtable 和 HBase 比较少见到,一般一个 column family 的 columns 都符合同一种数据类型。Bigtable 是列数据库,若干个需要一起访问的 column family 的列数据可以放到一个 SSTable 上面去。一个 column key 的格式是:
family:qualifierAccess control 和 accounting 都是在 column family 这一层实现的。
对于时间戳,对于相同 row key 和 column key 的数据,默认是按照时间戳降序排列的。GC 机制可以回收客户指定的较新的保留版本以外的所有版本。
SSTable 包含若干个 blocks,对于从 SSTable 中读取数据,有两种常见的形式,一种是映射所有数据到内存中,这样读取就直接访问内存就可以;另一种是使用二分查找索引找到对应的那个 block,然后读取 block。SSTable 是一个持久化了的映射表,而 tablet 则是一个 range 的行,这是两个不同层面上的概念。一个 tablet 可能数据来源于多个 SSTable。
Bigtable 也是 singler master 的结构,和 GFS 设计类似,为了给 master 减负,多数 client 可以直接去和 tablet server(每一个 tablet server 可以管理很多 tablets)沟通,而不需要经过 master。
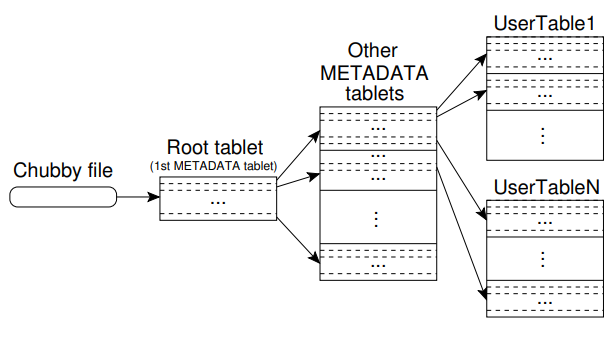
Metadata 也是存放在 tablets 里面的,但是它们设计得比较特殊,只有三层,并且 root 是不会分裂的,每一层都保存了下一层属于它的 tablets 的位置(root 的位置信息就保存在 Chubby file 中)。客户端会缓存 tablet 的位置信息,但是如果有了变化,它会到它的 parent 节点那里去找。
对于写数据,和很多追求高 throughput 的系统一样,使用 commit log 加上 batching write (group commit)。
Compaction 分为两种,
- 一种是 Minor Compaction,就是 memtable 的大小到一定值了以后,系统就会写入新的 memtable,原来的 memtable 会被转化为 SSTable;
- 另一种是 Major Compaction,就是把 SSTable merge 成为数量更少但是更大的 SSTable(之前在 SSTable 里被标记为已删除的数据行直接被丢弃),这也是异步进行的。
这是《常见分布式系统设计图解》系列文章中的一篇,如果你感兴趣,请参阅汇总(目录)寻找你其它感兴趣的内容。
文章未经特殊标明皆为本人原创,未经许可不得用于任何商业用途,转载请保持完整性并注明来源链接 《四火的唠叨》