这篇的内容是关于分布式消息队列的,无论是在实时系统,还是在非实时系统中,它都有广泛的应用。作为一个消息队列,基本的功能需求相对好描述,简单说有两条:
- 首先,围绕着 pub-sub 这样的机制,允许消息发布者发布的特定主题下的消息,能够投递到若干个订阅者。这条几乎是必选的。
- 其次,消息的有序性,既然是一个队列,那么消息满足先进先出(FIFO)的规则。这一条,部分实际场景方面并非必选。
非功能需求方面,这里面有几个基本的重要特性可以拿来考量,可以说这些基本都是分布式系统所共有的,但其中有几个是异步系统所更为看重的——比如说:
- Availability
- Security
- Consistency
- Throughput
- Latency
- Durability
- Scalability
- Resilience
当然,在实际应用中,一个分布式队列系统,并不只是为了出于异步系统处理的初衷而引入。比如还有一种常见的原因是——为了简化系统的依赖关系。比方说,一个大的分布式系统中,子系统 A、B、C 要依赖于子系统 D、E、F,复杂的依赖关系可能要求引入多种不同的接口、协议,但是引入分布式队列 X 以后,D、E、F 只需要提供事件给 X,而 A、B、C 只需要从 X 消费队列中的事件即可。整个系统得到简化。
系统的两端,有的称呼为 Subscriber 和 Publisher,有的称呼为 Consumer 和 Producer,含义略有区别,这里采用前者。
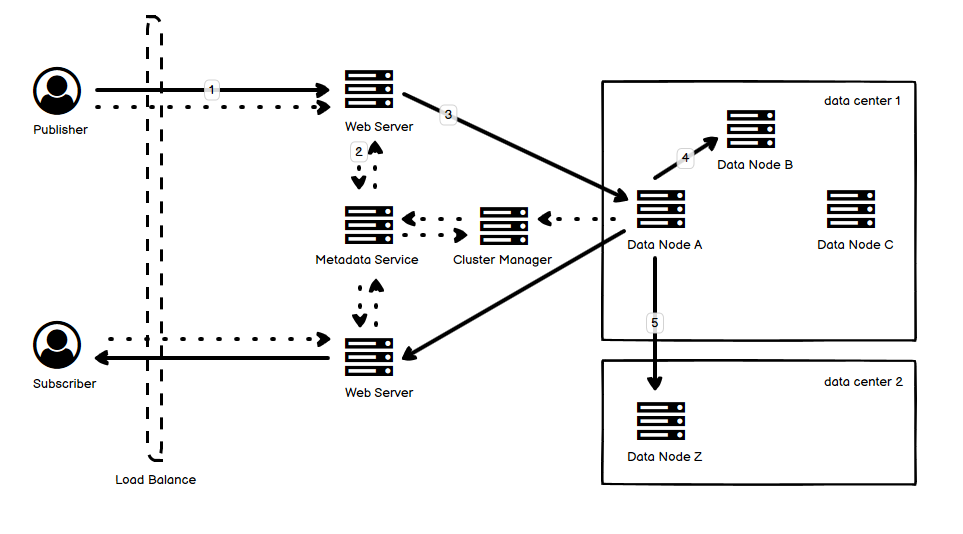
- 整体来看,一个 subscriber 对于一个 topic,享有自己专属的一个 queue。上半部分是消息发送入队列的过程,下半部分则是从队列中取出投递消息的过程。实线表示实际的消息数据流,而虚线表示控制流。
- 消息的实际数据存储和元数据(metadata)分开,消息发布者可以调用 Metadata Service 去创建主题,而消息订阅者可以订阅(创建队列)。Metadata Service 维护主题、队列和数据节点之间的映射关系。
- 消息发布部分,数据流动分别用数字 1 到 5 简单表示了。Web Server 先要去 Metadata Service 查询消息需要存放到哪个节点上去,得知是节点 A。节点 A 在收到消息以后还需要做 replication,一份数据存到同一个数据中心的另一个节点 B,而另一份存到另外一个数据中心的节点 Z。
- 节点通过 Cluster Manager(比如 Zookeeper)来管理,对于节点的变化,需要告知 Metadata Service,从而更新前面提到的和节点相关的映射关系。
- 消息订阅部分,也是先要去 Metadata Service 查询实际的节点,再去实际的节点读取。
- 同一个队列中的消息的相对顺序很重要,但是这个顺序的指定有两个思路:
- 发布者指定,因为消息的到达时间往往缺乏逻辑意义,发布者才知道谁先谁后。
- 根据消息到达时间由 Metadata Service 指定。对于多台 Metadata Service 实例的情况,队列 id 经过 sharding 后,保证都落到一个实例上,从而保证严格的保序性。如果存在多台实例,需要使用向量时钟等方式,这样的情形很少见。
- 去重方面值得一提,通常来说,有三种消息递送的等级要求,第三种是非常难做到的:
- At Least Once:消息至少发送一次
- At Most Once:消息发送最多一次
- Exactly Once:消息发送一次且只有一次
- 热门主题也是一个常见的问题,通常根据 queue 来做 sharding,就容易遇到一个问题,如果某一个(或者某几个)queue 特别热门,某些机器(实例)就会出现热点,解决的思路包括:
- 继续给该 queue 进行 sharding,从而分散其读写压力;
- 利用 replication,从而分散其读压力。
- 凡是涉及到消息通知,都可以涉及到 pull vs push 的讨论,对于消息队列这样的异步系统来说,前者要常见得多。
这是《常见分布式系统设计图解》系列文章中的一篇,如果你感兴趣,请参阅汇总(目录)寻找你其它感兴趣的内容。
文章未经特殊标明皆为本人原创,未经许可不得用于任何商业用途,转载请保持完整性并注明来源链接 《四火的唠叨》