今天是介绍 Proximity 系统,我不知道怎么翻译恰当,就保留英文原文。虽说词义上说的只是 “相似度”,但多数说的是 “地理” 上的相似度。因此,这一类系统多为基于地理上的邻近程度来提供服务的,核心功能就是要找到某人、物或地点地理位置附近的其它人、物或地点。比如像打车系统 Uber、滴滴的叫车功能,比如像大众点评、Yelp 或者百度地图、Google Map 中寻找附近餐馆的功能,或者是 “ 附近的人” 之类基于地理信息的 app 上的小功能。
从读写的角度看,基本上这类功能都要存储位置信息,基于位置的 “寻找” 是很核心的需求,因此读往往比较重。但是写的话差异就比较大了,像有一些应用,比如打车系统,需要司机和乘客双方匹配,而且双方又往往在地理位置上的移动中,因此每几秒钟就要汇报并记录一下位置,有非常重的写;但是像 “寻找附近餐馆” 这样功能,匹配双方至少有一方基本上地理位置是固定的,往往就不是这样了。
在这里我们选择其中相对较复杂的打车系统来讨论。
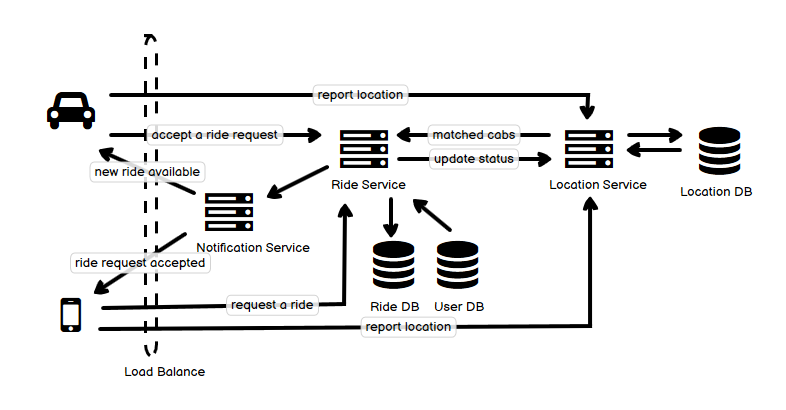
- 大的功能上面,它包括两个部分。一个是单纯的位置汇报,比如每 10 秒钟,司机和乘客都要汇报自己的当前位置(经度和纬度),这也是图中最上面和最下面的两个横着的箭头,汇报给 Location Service。
- 第二个是这个打车的流程。乘客发起一个打车请求,Ride Service 收到以后,去 Location Service 找一个范围内的 available 的车,然后按照根据距离的顺序,通过 Notification Service 向司机发送通知。为了提高效率,可以同时发送给几个司机,让司机抢单。司机收到并接受请求以后,Ride Service 让 Location Service 更新司机的状态为 unavailable, 再通过 Notification Service 告知用户正式匹配到的车。如果找不到司机,扩大搜索范围去 Location Service 继续寻找。
- 这里司机也好,乘客也好,和 Notification Service 的连接,使用 push 模型,可以通过 long poll 或者 socket 连接实现。
- 打车的信息存放在 Ride DB 里面,这个数据库可以是一个 RDB,也可以是一个 KV 的数据库。
- Location Service 的实现是一个 Proximity 系统的核心。在这里它主要要做两件事,一个是接受司机和乘客位置的汇报并记录;一个是接受 Ride Service 的请求,返回一定范围内匹配到的 available 的司机。
- 这个匹配机制有大致有这样两种实现方式(之前在这篇文章中都提到过):
- 一种是使用 QuadTree,就是说把地图上任意一个区域都划分成四个子区域,每个区域如果节点超过一个阈值,就继续划分。
- 第二种是使用 Geohash,本质上就是降维。降维的原因是,一维的数据管理和查找起来要容易得多,二维的数据要做到高效查找比较困难。我们的查找条件是基于经纬度的,而不是一个单值;我们存储的数据也都是一个个经纬度形成的点,因此,Geohash 的办法就是把查找条件和存储的数据全部都变成一个个单值,这样就可以利用我们熟悉的一维数组区域查找的技术来高效实现(比如把它索引化,而索引化其实是可以通过 B+树来实现的,因此 Geohash 的查询时间复杂度和 QuadTree 是可以在同一个数量级的,都是 log n)。
- 由于写的频率太高,可能导致上面的树(无论哪一种)出现节点分裂和合并过于频繁,造成性能和资源竞争的压力,因此可以做两个优化:
- 这个 location 数据的写入,可以不非常实时,比如对于没有处于接单状态的司机,可以合并几次写入到一次再写入。
- 节点的分裂还是合并设置阈值,并且分裂阈值要大于合并阈值,阈值以内不发生节点变化。比如说,一个大节点的下一层,同样数量的司机,可能分布在 x 个子节点,也可能分布在 x+1 个子节点。
这是《常见分布式系统设计图解》系列文章中的一篇,如果你感兴趣,请参阅汇总(目录)寻找你其它感兴趣的内容。
文章未经特殊标明皆为本人原创,未经许可不得用于任何商业用途,转载请保持完整性并注明来源链接 《四火的唠叨》
楼主的图是拿什么软件画的呀
Balsamiq