输入建议系统,指的就是 “typeahead”,比如 Google 搜索,输入一个单词的前几个字母,后面最常用的几个搜索词会被联想出来。有时,它也需要具备一定程度的字符拼写错误自动更正能力。
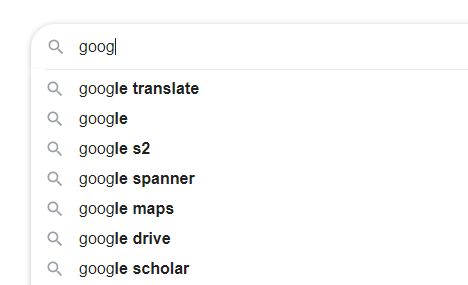
比如上面这张截图,我输入了 “goog”,在输入框的下方列出了最常见的几个以 goog 开头的搜索短语。
- 这个功能可以说不是搜索系统的核心功能,而且要求响应一定要非常迅速,考虑到无法避免的网络延迟,我们希望服务端的处理越快越好。响应数据不用非常准确,但是延迟响应肯定是一个糟糕的结果。所以我们希望服务端的处理的数据尽量都在内存中,几乎不需要怎么读取磁盘,整个过程也要保持简洁。
- 用户侧的浏览器方面,有这么几件事情比较重要:缓存之前的提示数据;
- 数据不一定只从服务端返回,浏览器也有本地的历史查询记录(比如 Cookie),提示列表可以是二者的并集;
- 用户打开页面或者选中焦点框就要开始建立连接,从而在输入后节省连接建立时间;
- 用户每输入一个字符,不要马上去询问服务器,而是等 100 毫秒,没有接着敲字符再发起请求;
- 由于无法预料响应到达后是否输入串已经发生了变化,因此响应到达后要比较当前用户输入串是否是查询串,只有二者一致才要显示返回结果。
- 为了尽量减少延迟,又考虑到一致性要求不高,CDN 是一个很好的选择。新生成的 Trie 树被推送到离用户较近的节点去。
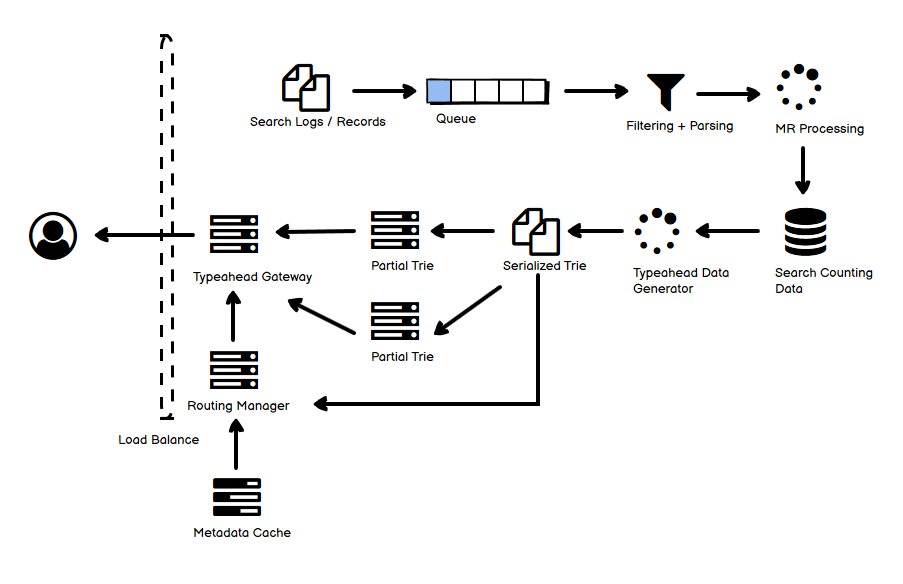
- 再来看服务端,大致分为三个步骤。
- 第一个步骤是图中上面一行,用户的搜索数据或搜索日志,被异步系统处理并计数,写入右侧的数据库中,这个数据库可以考虑选用列数据库(比如 HBase),以提高批量处理的效率,主键可以是一个按序的时间段,以便后续处理。不需要统计全部搜索数据——可以是一个采样以降低数据规模,提高效率;也可以设置一个阈值,如果搜索次数低于阈值就忽略。
- 第二个步骤是图中第二行靠右侧的部分,每隔一定时间,根据统计数据生成 Trie 树,并持久化到版本化的文件中。为什么用 Trie?因为对于输入建议这种需求,基本就是一种 “前缀查询”,经过压缩的 Trie 树查询的效率很高(其实 HashMap 也可以,但是对于 key,也就是输入前缀的空间占用非常浪费)。
- 第三部分,考虑到树比较巨大,可以分布在若干个节点上,它的更新异步进行,即整棵树构筑完毕以后整体替换,而不是操纵正在被使用的单个节点。
- 具体哪一些节点来负责树的哪一部分,这是一个策略问题,它由 Routing Manager 来决定,但是目标是尽量让请求均匀地分摊。比如前缀为 a~bc 的去集群 Partial Trie A,前缀为 bd~d 的去集群 Partial Trie B……这部分可以结合 Zookeeper 来实现。
- 请求到来的时候,先到达 Typeahead Gateway,而具体请求分发的策略要根据 Routing Manager 来定,这个策略不需要每次都现询问,而可以本地缓存,定期更新。
这是《常见分布式系统设计图解》系列文章中的一篇,如果你感兴趣,请参阅汇总(目录)寻找你其它感兴趣的内容。
文章未经特殊标明皆为本人原创,未经许可不得用于任何商业用途,转载请保持完整性并注明来源链接 《四火的唠叨》