我记得在毕业以前,就大致明白这样一件事情,系统之间、模块之间的交互,要确定协议,要定义接口,兜兜转转这些年过去了,我觉得对这件事情认识当然越来越深刻,也说不清其中的程度。最近做的项目中,开始大量地和 OpenAPI 打交道,一方面要最先使用 OpenAPI 来定义接口,让多个其他交互的模块都遵循它来开发,就是 “OpenAPI Driven Development” 的意思,这没啥特别的;但另一方面,系统中还需要把 Protobuf 接口定义转换成 HTTP 接口定义,并实施地使用 swagger-core 来动态创建 OpenAPI Spec,这就比较好玩了。

gRPC 到 HTTP 的协议转换
先
[……]阅读全文
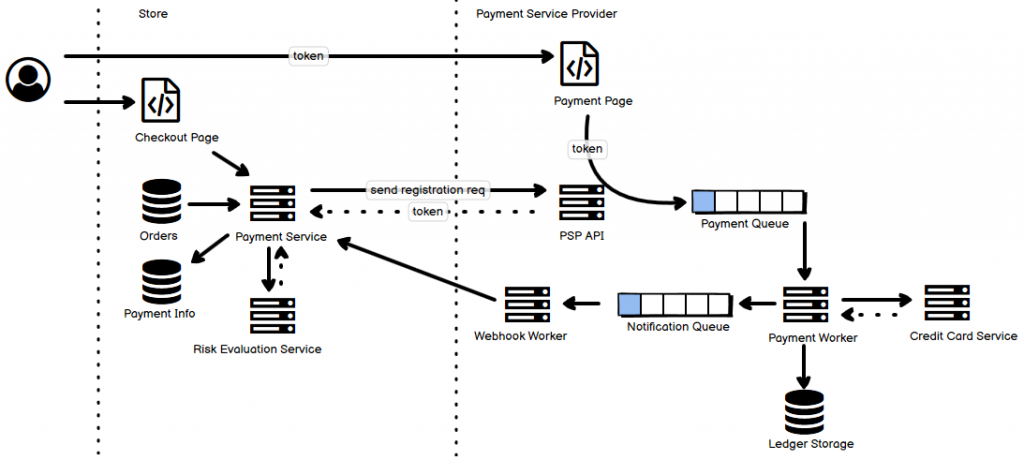
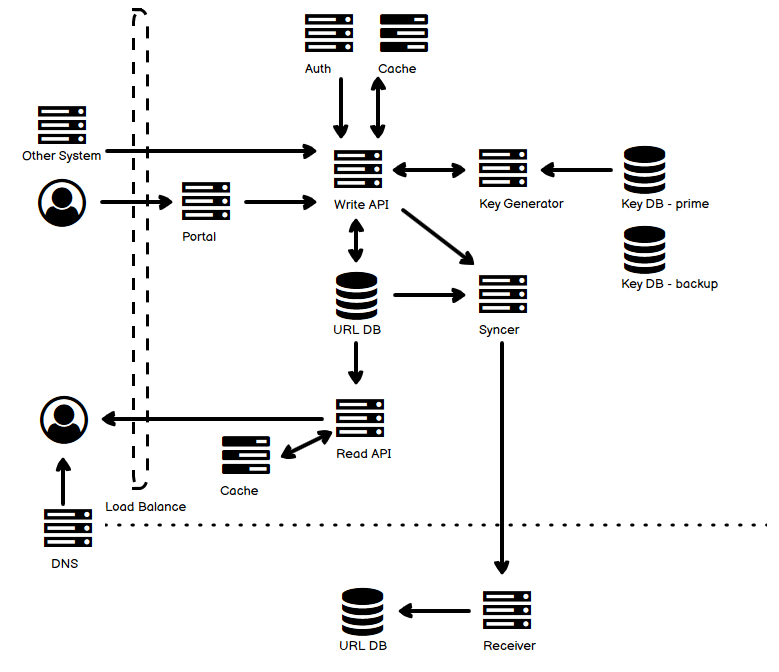
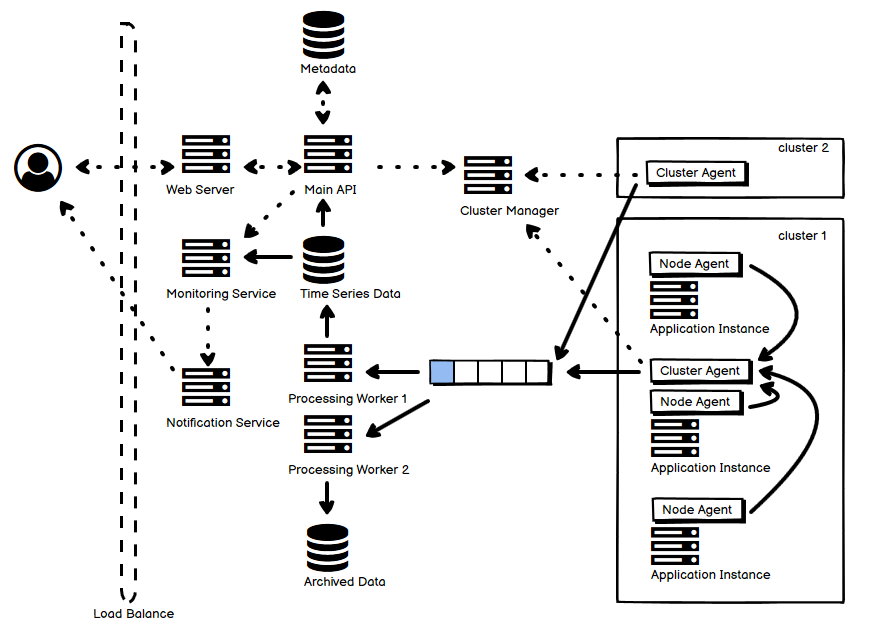
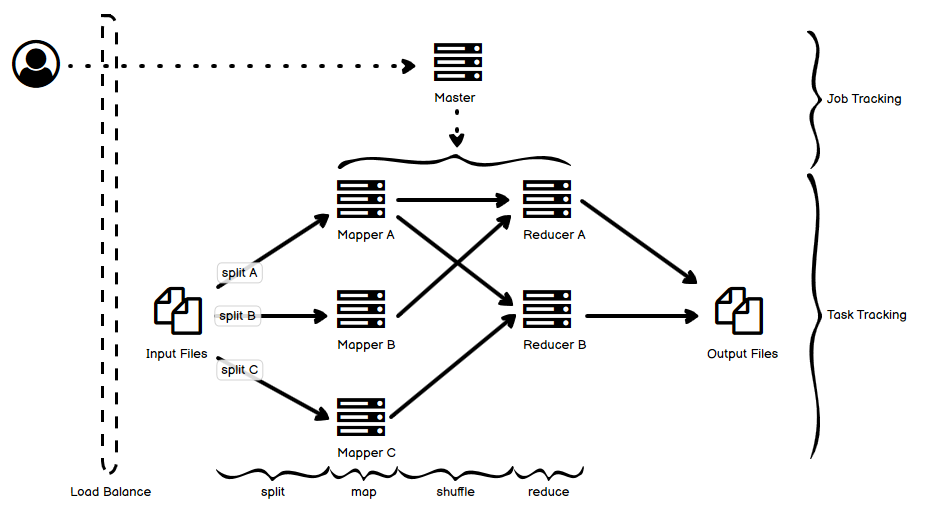
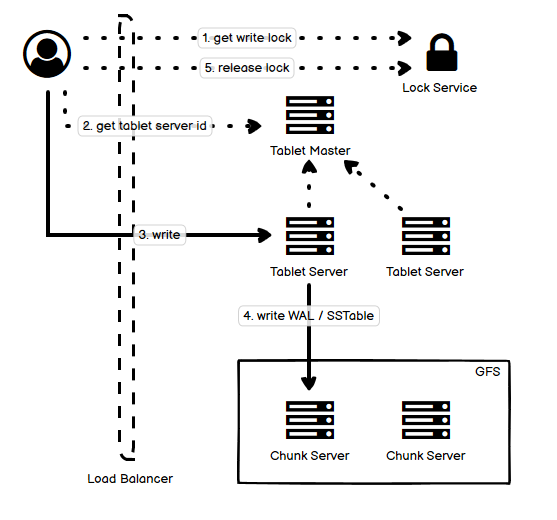
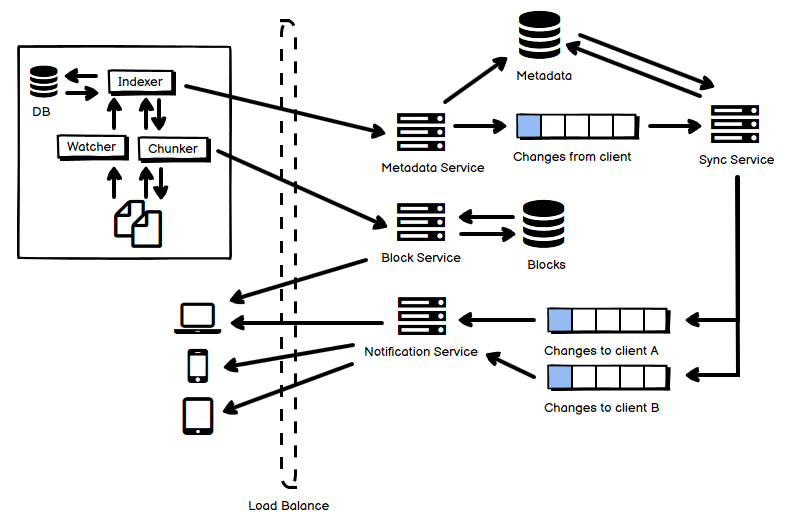
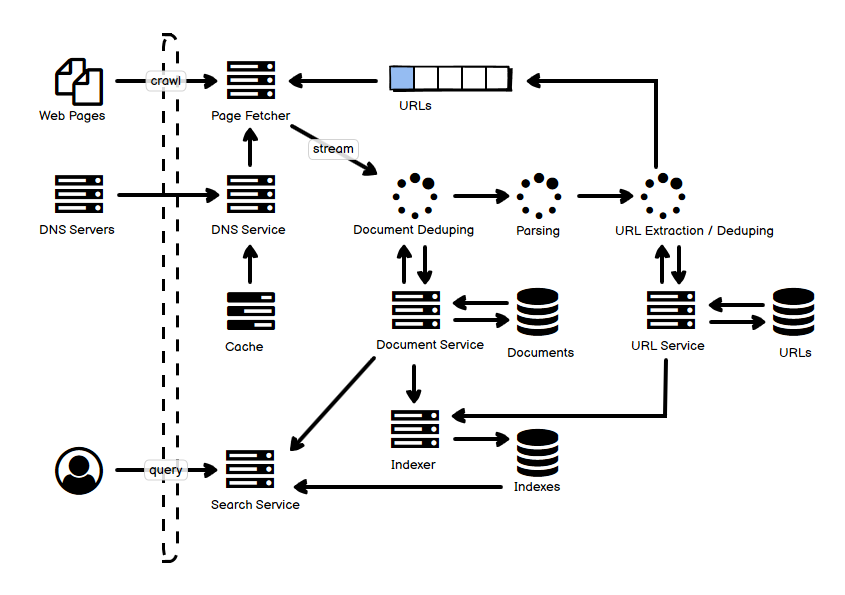
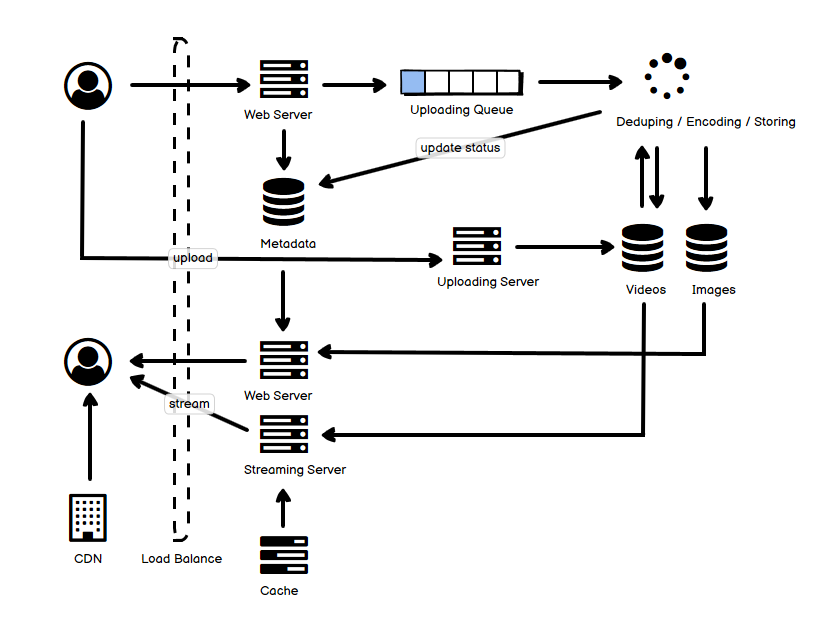
 如同我在第一篇文中说的那样,自己在学习各种各样分布式系统的过程中,做了一些笔记,也有自己的理解,把它们放到一起,用一张图选择最主要的部分来阐释,从我的角度来说,是能够帮助理解和记忆的。事实上,遇到的很多各种各样的分布式系统,绝大多数都逃不出那最常见的十几种,也就是说,逃不出这些 “套路” 和 “玩法”。这就是把它们整理成一
如同我在第一篇文中说的那样,自己在学习各种各样分布式系统的过程中,做了一些笔记,也有自己的理解,把它们放到一起,用一张图选择最主要的部分来阐释,从我的角度来说,是能够帮助理解和记忆的。事实上,遇到的很多各种各样的分布式系统,绝大多数都逃不出那最常见的十几种,也就是说,逃不出这些 “套路” 和 “玩法”。这就是把它们整理成一