这一篇是记录分布式工作流系统的。我这些年来参与了几个不同的分布式工作流系统的工作(以前从另外的角度写了一些总结放在这里),大部分是基于基础分布式工作流引擎二次开发的,但也有从头开始实现一个的。总的来说,从原理上看可以说它们的实现是大同小异,大致是基于 Amazon 的 SWF 的各种实现变体。
从功能需求上看,一个工作流系统,当然是要完成一个工作流的执行和追踪,因此,它的用户,可以定义工作流的逻辑,启动、停止工作流,并能够查询工作流的当前执行状态。但我觉得有一条需要着重强调——自治(Autonomy)能力。分布式工作流系统通常来说,要比其它常见的分布式基础设施,从用户理解的角度来说,要复杂和困难一些。因此提供好的自治能力可以降低维护工作的开销,这样的自治能力包括:
- 定义和描述工作流依赖和执行逻辑的能力,有的工作流系统甚至提供可视化的定义工具。这样的能力也包括自定义的可扩展任务的定义和部署的能力,因为系统预定义的执行任务类型总是很有限,用户要求其扩展性是必然的(比如某通知步骤,系统预定义允许发邮件通知,用户要求自己实现发短信的功能)。
- 干预工作流执行的能力,比如要暂停、恢复、停止、取消一个工作流的执行,甚至给工作流的执行发送消息。
- 工作流执行的查询能力,既包括单个工作流状态的查询,也包括基于输入、输出和执行日志、路径等更高级的查询能力。好的工作流系统,总是可以给出一个非常清晰直观的执行状态可视化展示。
从非功能需求上看,当工作流系统成为分布式的基础设施,那么除去我们长谈论的那些分布式系统的基本特性和要求,还有这样几个尤其重要:
- 首先是吞吐量,经常是由于吞吐量的要求,系统才被迫考虑使用分布式的方式实现。
- 其次是 SLA,对于这种对外提供服务的系统,这是一种定义用户承诺的方式。
相对来说,单次执行的响应时间等等反而不那么重要了。
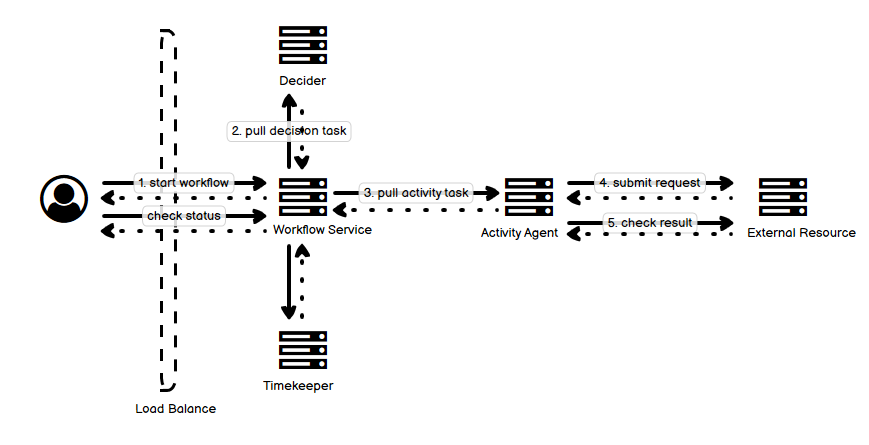
- 上图中,从整体来看,中间的 Workflow Service 是核心,也是整个工作流系统唯一暴露给用户或其他外部客户端的组件。用户可以向 Workflow Service 提交工作流的定义,要求启动和停止工作流,或是询问工作流的执行状态。实线表示请求,虚线表示响应。
- 其它的核心组件围绕它来工作,并且是使用 pull,而非 push 来获取任务并执行
- 这种方式保证了每个工作的组件可以根据自身的不同情况去核心 Workflow Service 中认领任务,而 Workflow Service 不需要追踪每个组件各自的状态,提高了系统的可伸缩性。
- 使用这种方式保证了无状态的特性,所有的组件都可以挂掉,因为没有任何状态的记录。所有的状态都记录在 Workflow Service 的存储系统(未画出)之中。
- 系统中执行的任何任务,包括用户定义的任何步骤,都必须是幂等的,因此都是允许被反复执行的,这种方式使得系统得到简化。
- 除了 Timekeeper 所有组件上的任务执行,都必须伴随心跳(未画出)一起工作,因为任何一个任务执行都可能出现异常状态。心跳的发送主要有两种方式,一种是管理任务执行的各自的工作进程(线程)自己发送,还有一种是由某一进程(线程)统一发送。
- Decider 是任务逻辑大脑,它只做一件事,就是根据当前工作流定义和执行的状态(包括所有任务的状态、上下文等等),来决策 “下一步” 应该做什么。
- Activity Agent 是执行实际任务的 worker,它只关心自己任务的执行,而对整个工作流的步骤一无所知。不同的 Activity Agent 可以优化设计为处理不同的任务。
- 图中的例子中,Activity Agent 自己没法完成某一些工作,但可以将工作委托给外部资源去做,而自己负责监控该资源的状态,从而掌管该任务的执行。这个部分,有时候还需要引入分布式锁(未画出)来保证资源征用的排他性。
- Timekeeper 用来管理不同的定时任务的执行,这样的定时任务在工作流系统中非常多,例如前面提到的,所有任务都有执行超时时限,所有任务的执行都有心跳超时时限。Timekeeper 保证超时出现时,任务能够得到重新部署或执行其他相应的逻辑。
- 一种是基于 key 和时间段的查询,比如可以使用关系数据库实现。那么定期查询数据库,找到接下去时间内要触发的事件,上面说的 Timekeeper 就是基于这种方式。这种方式的好处是这个事件的触发时间可以灵活修改,而且查询条件的定制能力比较强。
- 还有一种是严格的 FIFO 队列,比如可以用 Kafka 实现。方法就是把未来的时间划分成若干个时间段,每个时间段对应一个 queue,越接近现在的时间这个时间段越短。比方说,有这样几个 queue:0 (now)~2^2 秒,2^2~2^4 秒,2^4~2^6 秒……然后不断有 job scan 整个队列并把到时间了的 events 从一个更未来的队列倒到一个更接近现在的队列。如果有新的事件加入,那就根据设定的触发时间来把它加到相应的队列里面。这样一来,整体来看,这些队列保证了事件大体上是有序的,但是每个 queue 的事件是无序的。这种方式限制比较多,一旦事件放到队列里面以后,就没有办法轻易修改(包括触发时间的修改),但是好处是它的吞吐量可以非常大。
这是《常见分布式系统设计图解》系列文章中的一篇,如果你感兴趣,请参阅汇总(目录)寻找你其它感兴趣的内容。
文章未经特殊标明皆为本人原创,未经许可不得用于任何商业用途,转载请保持完整性并注明来源链接 《四火的唠叨》
第二种是时间轮设计