这一篇记录分布式的流量控制系统。
首先,关于流量控制系统,从功能性需求上考虑,它涉及到使用怎样的规则去限制流量(基于 IP、用户 ID、地域,等等),以及,流量超出限制以后的策略是怎样的(比如返回 HTTP 429 或者带有 ratelimit 的 HTTP headers,queue,客户端 retry with exponential backoff 等等)。其中一个基本的问题是,流控在客户端做还是服务端做,通常来说,服务端是一定要的。对于存在的形式,有的流控功能可以以一个 lib 依附于 app 执行,有的则可以通过一个 service 来实现。
其次,从非功能性需求上考虑,比方说系统的可靠性,增加 latency 的限度等等。对于单机系统,有一些比较成熟的流量控制算法,比如 Leaky Bucket,或者 Token Bucket,我在专栏文章中曾经介绍过。再来说分布式的系统,除去我们经常考虑的分布式系统的特点以外,还需要强调对于流量控制的精度要求这一方面。
为什么要提这个精度要求,是因为对于精度要求的不同,我们可以把需求分成两大类。而这两类的分布式流控在实现上,会比较不一样。
- 类型一:用于 “保护系统” 的流量控制。这一类,精度要求不高。比如说限制每秒钟处理 100 个请求,放进来 110 个也没什么大不了的,而且也不在乎这个请求是哪个用户发送过来的。
- 类型二:用于业务事务的流量控制。这一类,要求就相对较高了。比如说,涉及某些精确计费,针对单个用户,10 个请求还是 11 个请求是不可以出错的。
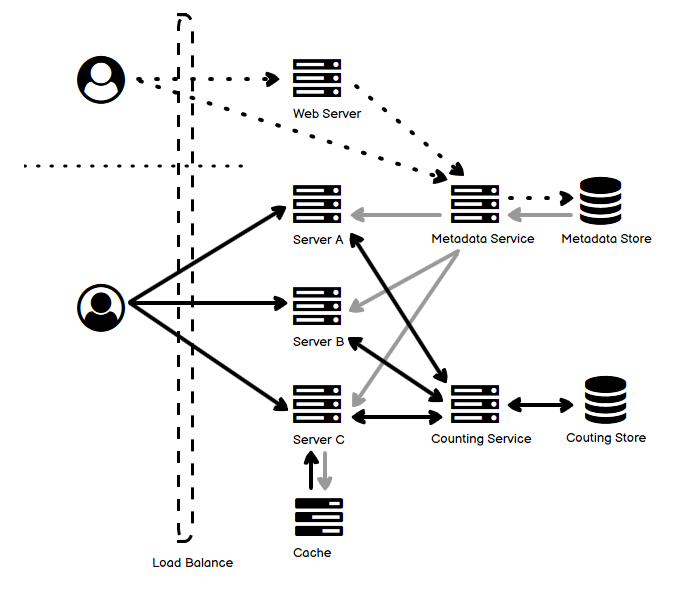
- 上图可以分为三个部分,分别具有三种不同类型的箭头:
- 上半部分的虚线表示的是系统管理员,通过 Web UI 或者通过命令行等非 UI 方式创建和更新流量控制的规则。这一类数据叫做 Metadata,通过单独的 service 和数据库维护。
- 右半部分的浅灰色箭头,表示的是这样的规则,通过 push 或 pull 的方式同步到流量服务器(流量控制可以和业务逻辑部署在同一台机器上,也可以分开)的缓存中。如果实时性要求没有特殊要求,异步 poll 是比较简易的方式。
- 实线黑色箭头,描述的是,用户业务请求到来之后,Server A、B、C 来进行流量控制的过程。如果有流量额度,就允许请求处理,否则根据规则进行拒绝或者入等待队列等操作。注意的是,前面说到的类型一和类型二,对于精度要求不同,这里的实现也有所区别:
- 对于类型一,精度要求低,A、B、C 定期地、异步地将当前的流量消耗发给 Counting Service,并从 Counting Service 获得剩余的流量空间。这种情况下,由于延迟行为造成的不一致性,流量空间有可能出现负数。但是这种方式对于原请求的性能影响较小。
- 对于类型二,精度要求高,那么需要保证(比如通过 id 的 sharding 或者 session stickiness)同一个用户的请求落到同一台 Counting Service 的机器上去,计数往往需要加锁来保证并发下数量的准确。也就是说,这个验证过程是同步的,那么这种方式往往对请求处理的性能影响较大。
- 上面介绍的这种数据通信方式,是借助了 “第三方”Counting Service 来记录当前不同用户的请求量,但它也有一些其它备选方案,可以避免这个第三方的引入。比如说,可以使用 Gossip 协议等点对点协议来向其它的节点同步本节点的流量消息,也可以藉由已经存在的协调服务来简化这个过程等等。
- 对于 Counting Service,为了保证对于请求处理的影响尽可能小,它的 latency 就要越短越好,在一致性要求不高的情况下,可以选择内存数据库或者使用内存缓存的方式。而通信协议,也可以使用 UDP 来代替 TCP。只不过注意的是,考虑到消息丢失的情况,同步的数据至少要包括定期的 “全量数据”,而不要全部采用 “增量数据”。
这是《常见分布式系统设计图解》系列文章中的一篇,如果你感兴趣,请参阅汇总(目录)寻找你其它感兴趣的内容。
文章未经特殊标明皆为本人原创,未经许可不得用于任何商业用途,转载请保持完整性并注明来源链接 《四火的唠叨》