这篇是讲数据监控系统的,常见的包括 Datadog 和 Prometheus 等等。一个比较完整的数据监控系统要包括数据采集和数据展示两个部分。在此基础上,还可以具备告警和其它数据处理的功能。
对于监控的数据, 通常包括两类,一类是操作系统层面的数据,比如 CPU、内存、IO 等等;还有一类是应用相关的数据,这些数据就具备明确的业务意义了。
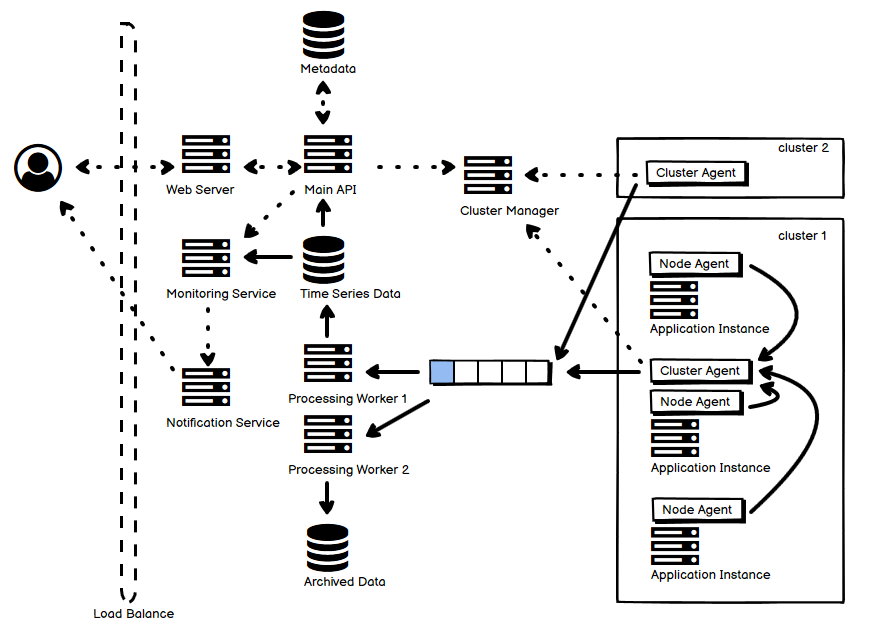
- 大体上,图中虚线表示控制流,而实现表示实际的统计数据流向。
- 用户通过 Web UI 来查看数据、定义规则,这些元信息存储在图中上方的元数据库中。
- Cluster Manager 和不同集群内的 cluster agent 通信,agent 通过心跳的方式和 manager 保持连接。
- 每个集群中,每个节点都有 node agent 负责采集数据,并将它们汇报给 cluster agent,cluster agent 汇总后写到一个队列中,也可以使用专门的数据流处理服务,后者实时性更高。
- 这个队列或是数据流有多个订阅者,它们从中读取数据并执行相应的操作,比如生成压缩数据,或者生成时序数据。
- 时序数据既可以被用作主要的数据展示数据来源,又可以被 Monitoring Service 拿来用作告警的判断之用。
- 这里面接收 metric emission 的核心服务,也可以不通过这种队列+worker 的方式来实现,而是就作为一个普通的 service,但是这种需要有比较高的性能要求(吞吐量),数据还不能丢。其中一种方法就是使用 WAL,然后最近的数据在内存中存放,攒够一批 merge 并写入存储。
时序数据大概是这个样子的:
时序数据的 schema 大致是这个样子的:
(name, label(name, value)*, time, value)*
就是说,一条数据有一个名字,接着是 0 到 n 个的 label,相当于是数据的除了时间以外额外的维度,再是时间戳和具体的值。我们的 metric 大多是由一堆这样的数据构成的。
举个例子,一个 service,要求统计请求处理的 latency:
("application-A", "path"="/record", "method"="get", 1726519187665, 233),
("application-A", "path"="/record", "method"="post", 1726519187667, 57),
("application-A", "path"="/record", "method"="get", 1726519187680, 462),
...
对于每一个请求,都有 HTTP path 和 HTTP method 两个额外的维度。
数据监控系统中使用到的时序数据,往往由这样的读写特点:
- 写大致是基于时间顺序的,但并不是严格保证的;
- 数据很少修改,一般都是 append;
- 主要的查询通常是基于时间范围的,就是说,总是先选取一个时间范围,然后获取数据;
- 通常近期的数据获取比较频繁,历史数据很少查询;
对于这样的数据,如果采用传统的普通关系数据库来存储,可行,但是在数量比较大的情况下至少会有两个大的 concern:
- 一个是存储成本;
- 另一个是查询的效率。
所以,在专门的 TSDB 之外,还有一些出于解决上述 concern 的目的,而基于普通的 RDB 进行扩展优化的方案。比如说,这个使用列压缩技术的例子,其实就是把行数据库变成列数据库(行数据库通常适合 OLTP 系统,而列数据库适合 OLAP 系统),来继续使用 Postgres 来存储时序数据。这种数据库的好处就是,它可以一定程度上同时适配行式数据库和列式数据库的需求。时序数据有一个重要话题就是数据压缩,因为时序数据库它往往存储类似性非常强的数据,比如连续时间单位内,数据的变化往往是渐进的,因此这样的数据很适合用增量压缩的方式来减小存储,Facebook 在 Gorilla 的论文里面详细介绍了这一点。
这是《常见分布式系统设计图解》系列文章中的一篇,如果你感兴趣,请参阅汇总(目录)寻找你其它感兴趣的内容。
文章未经特殊标明皆为本人原创,未经许可不得用于任何商业用途,转载请保持完整性并注明来源链接 《四火的唠叨》
精彩。一口气看完,感谢分享。