今天这篇是关于实时流处理(real-time stream processing)的,这一类的系统这几年比较多了,但相对而言并没有之前提到的几类基础设施系统常见。为什么说这类系统如今更为常见呢?因为一般说来,或者说曾经有一个普遍的认知,就是 throughput 和 latency 难以兼得的事实:
- 同步系统适用于响应实时性要求高的请求,处理实时性要求高的数据,速度快,处理过程中关注的数据粒度小,吞吐量也相对受限;
- 异步系统适用于响应实时性要求低的请求,处理实时性要求低的数据,处理过程中关注的数据粒度大,但是吞吐量往往要大得多。
可是,越来越多的系统需要大量的数据处理,往往需要上面二者 “鱼和熊掌兼得”,或者说,至少能够达成一个很好的平衡。分布式实时流处理系统就是这样的一个典型。
总的来说,流处理系统,都可以视作从一个基于消息队列的 pub-sub 系统演进而来的。实际应用方面,其实有很多例子。比如实时的数据分析,带有机器学习的日志分析。通用框架的话,像 Apache Storm 和 Spark Streaming 都属于这一大类。
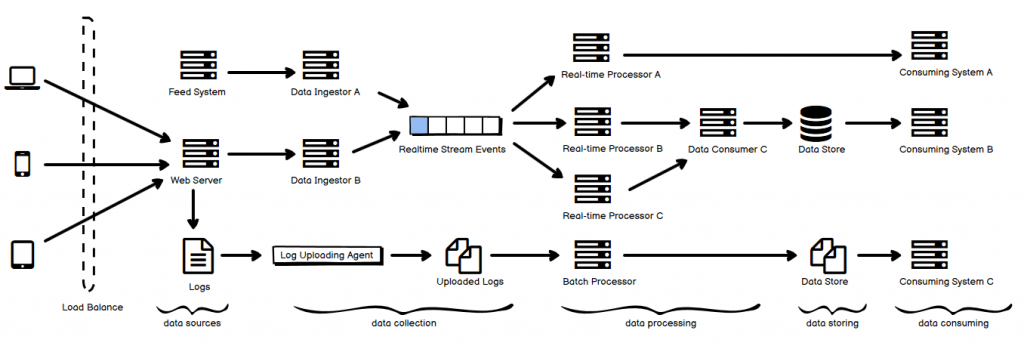
- 上面这张图简单表示了其中的一种典型的组件分布,上半部分属于实时性高的 streaming processing,而下半部分则是 batch processing。
- 从左往右看,最左边是数据源部分。用户通过不同的渠道访问产生了相应的数据,有一些是直接来自用户的操作数据,有一些是日志数据,还有一些来自其他 feed system 的数据。
- 这些数据通过不同方式收集,比如 Data Ingestor 用于集成到系统中去实时地获取数据,它可以是以被动的被调用的方式来收集数据,数据被即时发送到一个队列中;也可以以一个 agent 的形式在宿主机上工作,异步地完成数据收集(图中的 log 上传到某分布式文件系统中)的过程。
- 之后是数据处理的步骤,如果是 Real-time Processor,那就是即时处理的,当然,可以有多个这样的组件,通过 data stream 的方式连接起来;如果是 Batch Processor,那就是定时、批量处理的。
- 再就是数据存储部分,值得注意的是,某些实时数据处理可能跳过这一步,直接和再右边的 Consuming System 连接起来——这其实就是系统之间的耦合方式,可以通过数据流的形式耦合(包括简单 API 的形式),也可以通过 data store 来耦合,前者的实时性更高。
- 最右边是下游系统,比如日志分析的 UI,比如数据监控系统,比如报表系统等等。
Flink 的流处理,有一个 snapshot 机制(asynchronous barrier snapshotting)。在系统同时处理多个流的时候,有的快,有的慢,有的节点还会挂掉,为了协调整体的处理进度,它引入 checkpoint barrier 的概念,它在每条流中都设置有这样一个 barrier,较快抵达的流会等一等,等所有要求的流都抵达了这个 barrier,再继续往前走,原则就是前一个阶段的 operator 只能依赖于该阶段结束的 checkpoint barrier 对齐的时候所具备的所有事件,对齐之后做完 snapshot,记录下状态后,再继续前进。
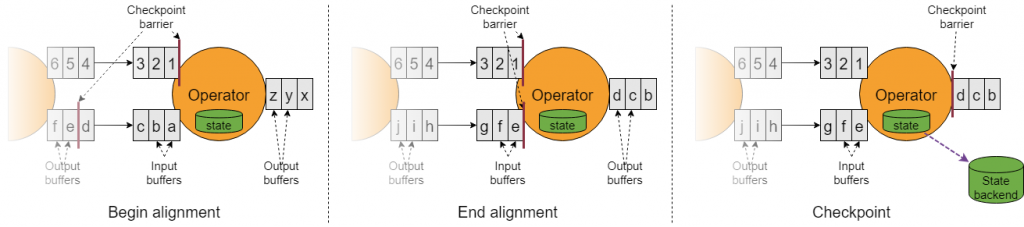
消息或事件投递有三种保证模式:至多投递一次;至少投递一次;以及投递且仅投递一次。对于 Flink 节点挂掉之后的恢复处理,也有三种保证模式:不从 snapshot 中恢复(对应 at most once);不丢失,但可能会存在冗余处理结果(对应 at least once);以及没有丢失且没有冗余(对应 exactly once)。上面的这个对齐机制就是对应这个 exactly once 的,这种情况下,事件可能会被处理若干次,但是每个事件只会最终影响 state 恰好一次。
这是《常见分布式系统设计图解》系列文章中的一篇,如果你感兴趣,请参阅汇总(目录)寻找你其它感兴趣的内容。
文章未经特殊标明皆为本人原创,未经许可不得用于任何商业用途,转载请保持完整性并注明来源链接 《四火的唠叨》