文件同步分享系统包括 Dropbox、Google Drive,也包括国内的各种网盘,比如百度网盘。总的来说,这里讨论的这个系统包含这样几个基本功能:
- 文件变更检测;
- 文件增量上传和下载;
- 文件分享和同步。
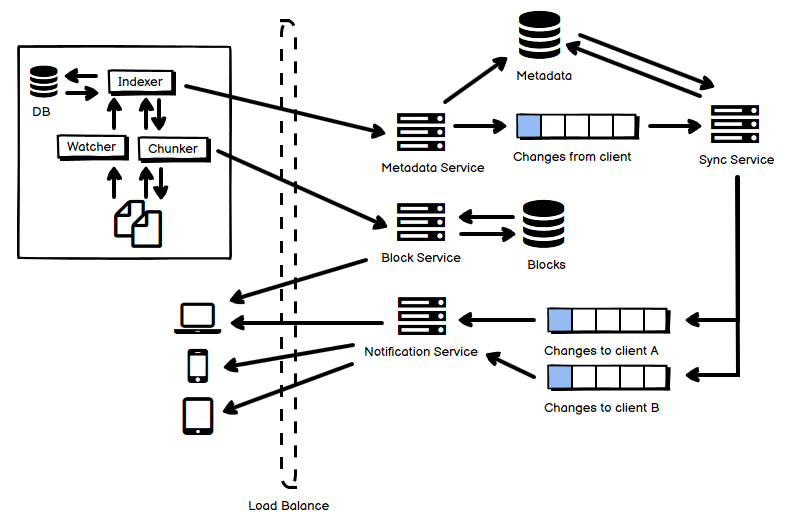
- 总体来说,上半部分是文件变化的检测和上传。上传分为两条路线,一条是控制流,一条是数据流。
- 客户端方面,包含这样几个关键组件和步骤:
- 有一个 Watcher 用来监控操作系统的文件变化,无论是 Linux 还是 Windows 都可以在文件系统上挂载回调,当文件系统发生变化的时候通知它。
- 有一个 Chunker 帮助给需要传输的数据分块,也负责将收到的 chunks 写入成为文件。对它来说它只负责听从 Indexer 的要求,处理 chunk 和文件之间的转换并进行文件系统的读写,属于数据流部分。
- 有一个 Indexer 是客户端的大脑,状态维持在一个客户端的数据库中,还要指挥 Chunker 通过远程的文件服务读写数据。客户端的变更元数据通过 Indexer 发送给服务端的 Metadata Service,它属于控制流部分。
- 服务端方面,上半部分是文件上传部分。由于一个客户端的数据变更而引起的文件上传的数量很可能不稳定,例如第一次的时候有可能要上传大量的文件,因此上传的文件需要通过队列缓冲。
- Metadata 需要放在一个数据库中,单条数据比较小,可以选用 KV 数据库+事务控制,或者 RDB+sharding。控制流部分告知要上传的文件,得到 Metadata Service 的批准以后,客户端直接向 Block Service 写文件数据。完成以后再告知 Metadata Service,并在 Metadata 数据库中更新文件上传的状态。
- 文件实际的数据按照块的形式组织,存放在分布式文件系统中。大文件拆分成小的块,这样如果某一个块的校验码(checksum)不匹配,重传该块即可,不需要重传整个文件。理论上文件去重也可以根据块通过特定的 hash 算法来进行,重复的块可以避免传输和存储来节约开销,当然,文件去重一定会面临着 collision 的风险,即便这个可能性再小它也依然是存在的。去重算法所得到的块 hash 串,不但在服务端存储,也在客户端存储。
- Sync Service 由队列中的数据驱动,负责同步逻辑,把需要同步的数据放到下半部分的若干个同步队列中去,每个客户端由于所在的文件系统状态很可能不一样,因此一般需要消费不同的队列。
- Notification Service 和客户端建立长连接,推送告知客户端需要同步的数据。移动客户端和桌面端不一样,可以告知需要同步的文件,但它不一定要时刻保持实际的文件同步,主要是考虑流量节约的目的。
这是《常见分布式系统设计图解》系列文章中的一篇,如果你感兴趣,请参阅汇总(目录)寻找你其它感兴趣的内容。
文章未经特殊标明皆为本人原创,未经许可不得用于任何商业用途,转载请保持完整性并注明来源链接 《四火的唠叨》
有个问题请教下, 为什么 metadata serivce 同步到其他客户端需要经过 sync service–>notification service, 但是 block service 是直连其他客户端的?感觉两者同步到其他客户端的逻辑应该一样
我是这样理解的,Notification Service 是负责通知的,这里面有多种场景,数据交互要复杂一些,比如可以用 long pull,宏观上看有一个服务端需要 “主动推送” 变更给客户端的行为。
但是 Block Service 就比较简单,完全被动,等客户端过来取数据。
非常感谢您的文章。有几个问题想向您请教..
client 的 db 是怎么用的呢。
我猜想了一个 workflow 不知道对不对哈..
watcher 检测到了本地更新-> 告诉 Indexer 需要更新远程->indexer 告诉 chunker,分片,然后返回给 Indexer 把更新的 chunk 信息写入本地的 db->indexer 去请求 metadata svc 说我想要更新远程 ,对比更新的 chunks,选定哪些 chunks 需要上传->chunker 收到指令向 block svc(storage) 传 -> 传送完成 block svc 确认 md5 checksum 之后告诉 indexer 上传完成 ->indexer 告诉 metadata svc 去更新 metadata(atom) -> 入队 (不太理解这里,不太理解什么数据进来,以及 sync svc 需要什么数据。。)-> 通知 sync svc -> 通知下游队列 (也不太理解)-> notify svc 告诉下游其他 client 该更新了
流程基本上正确。第一个队列其实就是文件的变更事件队列,说明哪些文件的哪些 chunk 发生了改变,这样 sync service 就可以根据它们和其它客户端的状态信息,来判定哪些客户端需要更新 chunk 了;后面的队列是每个客户端各自的更新队列,即前面所提到的哪些 chunk 需要更新了,因为每当有更新需要发生,你无法保证它会立即发生,需要有一个地方存放这样的更新事件。
请问这里的 queue 是不是位置不对?queue 按理解来说应该是放 block 的?Metadata 本身大小应该不大,个人感觉好像没有必要要用队列缓冲。
你说的是其中的哪个 queue?最上面那个 queue 当初引入的原因是,用户上传变更在这类系统之中,往往是批量且大量的(比如整个文件夹里面有成千上万个小文件),给系统的冲击很大,所以这个队列对于 metadata 的处理起到一个缓冲作用。