互联网搜索引擎都有爬虫系统,无论是 Google 还是百度。当然这里我们讨论的只是一个极其简单的版本。
对于爬到的资源,我们这里其实讨论的只是文本而已,还有图片、音频、视频这些媒体,如果我们也需要存下来,那就需要专门的媒体服务。对于媒体文件的存放,在之前的文中已经讨论过,这里就不再覆盖了。
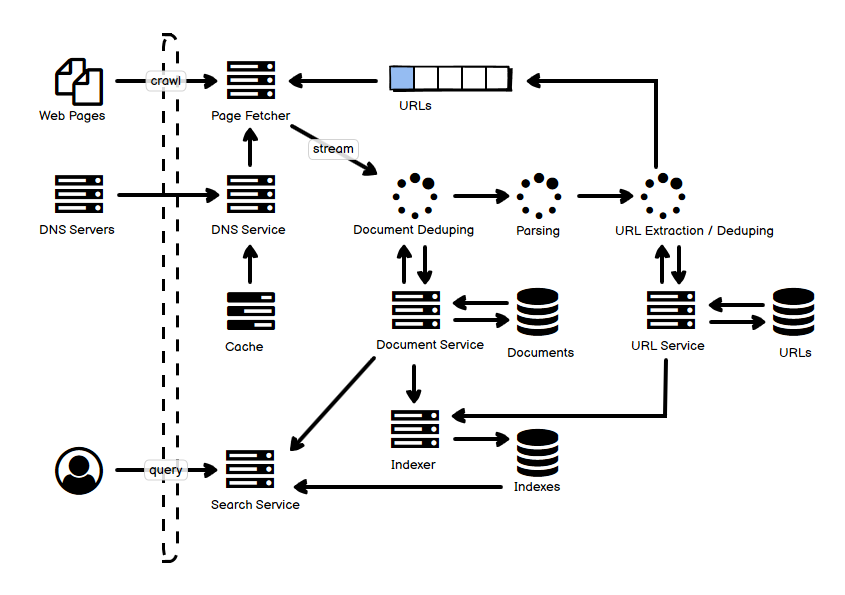
- 上半部分是爬取的过程,Page Fetcher 根据 URL 队列里面的事件来去实际的页面中爬取内容。不同的网站可以使用不同的 queue,配合从不同 queue 中 poll 的策略,这样可以合理分配资源,避免对某一个网站投入了太多的资源。爬虫需要解析 robot.txt,也要限制爬取的进程/线程数,保证不
[……]阅读全文