 入职 Coupang 两个月了,第一个月主要上手和开发 BOS(Business Operating System)系统,第二个月开始调研选型 ML Workflow 平台。前者目前来说相对比较简单,后者对我来说是一个新坑,也比较有意思,随便写写技术上的体会。
入职 Coupang 两个月了,第一个月主要上手和开发 BOS(Business Operating System)系统,第二个月开始调研选型 ML Workflow 平台。前者目前来说相对比较简单,后者对我来说是一个新坑,也比较有意思,随便写写技术上的体会。
先扯点题外话,其实这次求职有几个比较符合我预期的机会,可在思考之后,我基本上毫不犹豫就选择了 Coupang 这一家。最主要的原因,并非因为雇主,而是因为要做的事情。一个相当规模的团队,在大干一场的早期阶段,要在搭建起属于自己相当规模的 AI infra 来。
我觉得软件行业的巨大的变革,新世纪以来就三次,第一次是互联网应用的崛起,我太小没能做啥;一次是十几年前的 cloud,看着它从爆发式增长到如同水和电一样进入我们的生活,可我算是错过了它比较早期的阶段,即便相当长的时间内我在 Amazon,但是我却并不在 AWS;而这一次,当 AI 的浪潮再来的时候,我就很想行动起来,真正投身其中。程序员的一生能有几个赶这样大潮的机会呢,我不想再错过了。虽说我没有 AI 的技术背景,但我知道 ML infra 到 AI infra 却是个我可以切入的角度——从我最初接触软件开始,尤其是学习全栈技术的时期开始,我就认定,技术是相通的,这十几年来我一直在如此实践。因此在调查和思考之后,我觉得这是一个我不想错过,并且更重要的是自认为能够抓住的机会。
当然,就此打住,我目前只是这个领域的初学者,因此理解并不深入。
Why ML Workflow?
接着说正题,在这一个月之前,虽然我经历过不少关于 workflow 的团队,虽然我参与过从零写完整的 workflow 引擎,但这些都是针对于通用 workflow 而言的,我对于机器学习的工作流,也就是 ML workflow 可以说一无所知。于是在问题和需求调查的过程中,第一个关于它的问题就自然而然出现了,我们是否真的需要 ML workflow,而不是通用的 workflow 系统?
其实,这主要还是由于 ML 的生态所决定的。通用 workflow 可以完成很多的事情,但是在机器学习到 AI 的领域内,这个过程中最主要的目的就是把 raw data 给转换成经过训练和验证的 model,其中有很多部分都是有固定模式,因而自成体系的。举例来说:
- ML workflow 关注数据处理和 ML 或者 AI model 的生命周期,但是通用的 workflow 往往关注将业务流程自动化;
- ML workflow 需要将 artifact 管理、model registry、model insights 和 experiment tracking 等工具集成起来,但是通用的 workflow 往往是业务 application 层面的集成;
- ML workflow 执行的 task 往往需要高 GPU 使用和高内存,这和通常我们讨论的 workflow 的 task 对于 CPU 的使用完全不同。
总之,ML workflow 更像是一个 workflow 中的重要分支,它的特异性显著,因而从架构上它有很多在我们谈论通常 workflow 的时候不太涉及的特点,并且它们具有明显的共性。
ML Workflow 的固定套路
Workflow 这样的系统,和很多 infra 系统不同的地方在于,它具有全栈的特性,需要从端到端从用户完整的 use case 去思考。回想起通用的 workflow,我们会想,用户会去怎样定义一个 Workflow,怎样运行和测试它,并且怎样部署到线上跑起来。这其中的前半部分就是 development experience,而后半部分则是 deployment experience。
首先,对于 development experience 这个角度,ML workflow 有它独特的地方,其中最主要的就是 Python SDK。
通用 workflow 我们讲定义一个新的 workflow 的时候,我们通常都需要写一个 DSL,里面定义了一大堆 task 和依赖关系,而对于做得比较好的 workflow 系统来说,可能还需要一个可视化的 drag-and-drop 界面来方便地创建 workflow。
但是对于 ML workflow 来说,它最特殊之处是对于 Python code 的无缝集成。因为 Python 之于 ML 的地位就像是 Java 之于企业架构的地位,任何一个 ML workflow 客户端首先要考虑支持的编程语言就是 Python,用户通过往大了说是 SDK,而往小了说则是简单的 Python decorators,就可以定义 task 和 workflow。比方说,一个简单的 Flyte 的 hello world:
from flytekit import task, workflow
@task
def say_hello(name: str) -> str:
return f"Hello, {name}!"
@workflow
def hello_workflow(name: str = "World") -> str:
return say_hello(name=name)
在 ML workflow 的世界中,这是除了 DSL 和视图化之外的第三种定义 workflow 和 task 的方式,也是必须具备的方式。
第二个,对于 deployment experience 的角度,大致上是基于 Kubernetes 从 control plane 到 data plane 固定的交互机制。
我不知道这是不是一种关于 ML workflow 的约定俗成,但是通过调研 Kubeflow Pipelines、Flyte 和 Metaflow,我发现这三种对于 control plane 到 data plane 的交互模式是出乎意料地一致。
- KubeFlow Pipelines: client [KFP SDK] -> control plane [API Server -> K8s APIs (CRD changes) -> Workflow Controller / K8s Operator] -> data plane [K8s API -> creating Task Pods -> blob storage]
- Flyte: client [Flyte SDK] -> control plane [Flyte Admin -> K8s APIs (CRD changes) -> Flyte Propeller / K8s Operator] -> data plane [K8s API -> creating Task Pods -> blob storage]
- Metaflow: client [Metaflow SDK] -> control plane [Metaflow Service -> K8s APIs (CRD changes) -> Metaflow Scheduler / K8s Operator] -> data plane [K8s API -> creating Task Pods -> blob storage]
注:也有把 Operator 那一层归为 data plane 的,我觉得都说得过去。
其中 Metaflow 说的是使用 Kubernetes 集成的情况,因为它并不是非得依赖于 Kubernetes。
但大多数使用都是基于 Kubernetes 的,而且基本上都是这个套路,control plane 的 service 收到请求以后,通过创建 K8s CRD objects 的方式告知 workflow controller(scheduler)来执行 workflow,对于 task 的执行通过调用 data plane 的 K8s API 来创建 task pods 执行。
对于特殊的 task,需要交由特殊的 K8s operator 来执行,那么这个 “交由” 的过程,也是通过 K8s 这一层的 CRD change 来实现——Propeller 负责创建 CRD,而对应的 operator 负责 monitor 相应的 CRD 改变并相应地执行任务。Propeller 和 operator 二者互相并不知道对方的存在。这种方式对于保证 operator 的重用性和跨 workflow 系统的统一性简直是太棒的设计了,我们在 try out 的时候,就让 Kubeflow Pipelines 系统中的 operator,去执行 Flyte 给创建的 PTJob 和 TFJob。
关于架构,我觉得 Flyte 的这张架构图对于 components 层次的划分说得非常清楚,下面的 control plane 和 data plane 是可以有属于自己的 cluster 的,不过值得说明的是,真正最终执行的 task pods,也就是图中的最下面的 K8s Pod,也是可以放在另外的 cluster 上,由远程的 K8s API 调用触发的,这样就可以带来更多一层的灵活性:
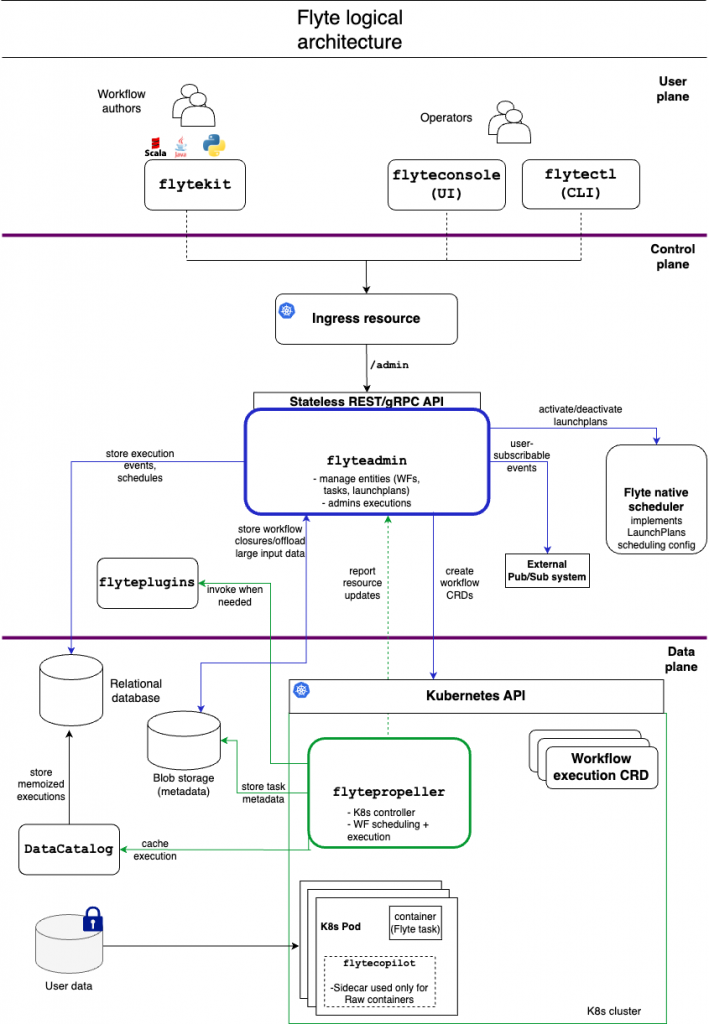
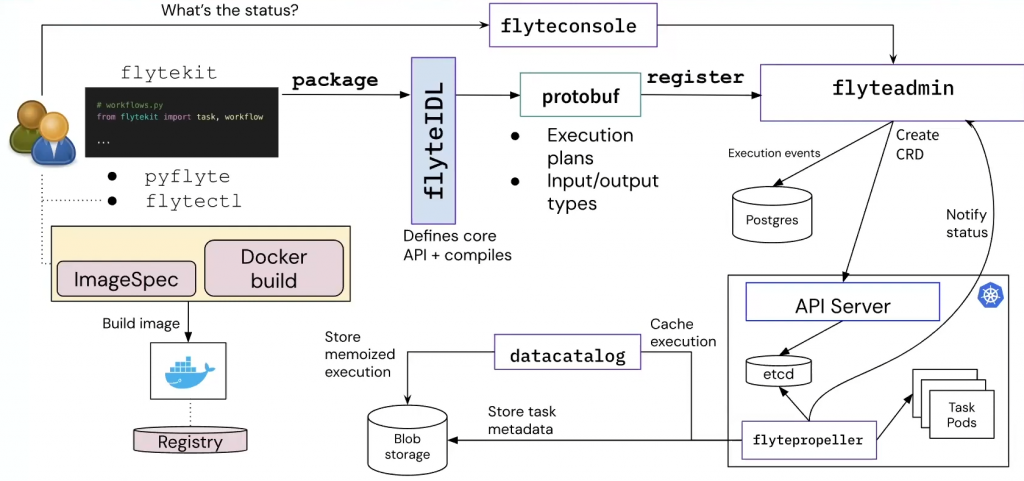
ML Workflow 的特性比较
再来比较这三个 workflow 的优劣,我并不打算列全,而是简单说说自己印象最深的几点:
- Kubeflow Pipelines 基本上有着最大的社区,因此它相对比较成熟,有自带的基于 CRD 的 K8s-native 的集成,因此可以直接跑 TensorFlow job 和 PyTorch job 之类的;UI 功能也比较强大,可以通过 drag-and-drop 来定制 workflow,也支持 yaml 文件创建 workflow。
- Flyte 最吸引人的是它的 Strong Typing,很多错误能够在编译期本地就能够发现(Kubeflow pipelines 和 Metaflow 都只是 hints);开发过程中,本地直接就能跑,而不需要什么 container;对于 multi-tenancy 支持得最好(比如 RBAC 和 tenant 的 Quota 机制)。
- Metaflow 的 setup 特别简单,而且本地可以直接调试;它对于 AWS 的一些 service 直接可以集成使用,特别方便(比如 Step Functions);Kubernetes 并不是一个依赖,也可以跑在 VM 上等等。
在我把这三者全部在 EKS 上搭了一遍并使用了一圈,也仔仔细细对别了特种特性和优劣之后,我对于 Flyte 的特性比较感兴趣,我觉得它们对我们团队也比较有用。
具体来说,很多区别但最重要的是两个:一个是 strong typing,其它两个都只支持 Python 类型的 hints,就这一点上,和一些 ML engineer 也讨论过,把问题发现在本地,是非常吸引人的;再一个是 multi-tenancy,对其 Flyte 有很多原生的特性支持,在平台完成之后,我们希望把平台上 ML 的能力开放出去,因此这是很重要的一个特性。此外,我也在考虑对于一个 control plane + 多个 data plane 这种 use case 的情况,这部分的需求还比较模糊,但是 Flyte 依然是这方面支持特性相对比较多的一个。
无论最后的结论为何,我希望我们能够比较灵活地部署选中的这个 ML workflow system,比方说,在 CLI 上,我们考虑在更高维度建立出一层,用户使用同样的命令,无论下面执行的 workflow 系统是什么,都不需要改变,这样一来,等到未来如果我们需要支持第二个,应该能够比较容易地整合进去。
文章未经特殊标明皆为本人原创,未经许可不得用于任何商业用途,转载请保持完整性并注明来源链接 《四火的唠叨》
很想了解大厂的架构/技术/工具选型是怎么做的,例如如何调研、如何决策等。