其实对于 MR(Map Reduce)系统来说,可能更重要的是分治和分步处理的思想,因为现在的基于 MR 的数据处理框架或者平台,在实现上数据处理往往已经和最经典的对于 MR 的理解(最早应该是来自 Google 的那篇论文)有了不少区别。当然,我还是按照之前的做法,把一个典型的 MR 系统简单图示画出来了,这个图相对比较简单。
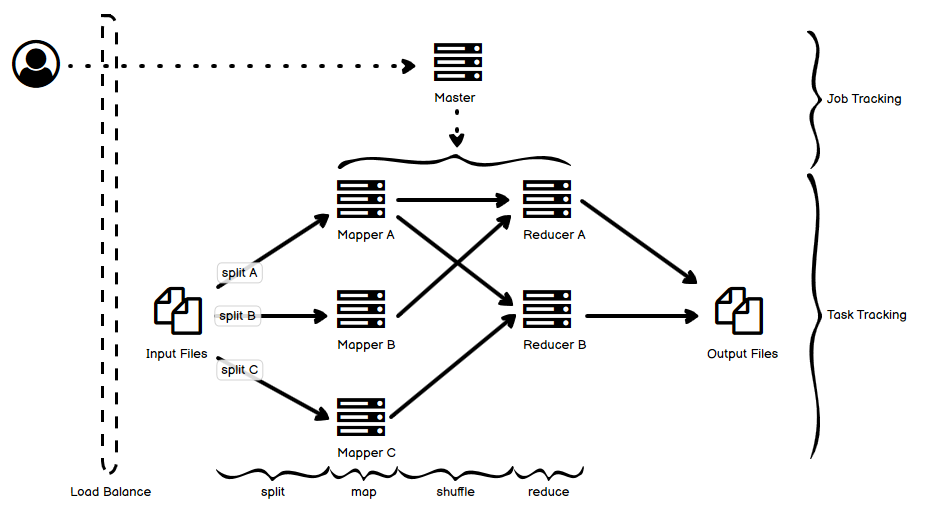
- 还是老规矩,虚线表示控制流,实线表示数据流。
- 上半部分用户向 Master 这个 job 管理节点提交一个 job 的请求,这个请求被拆解为若干个 task,下半部分的 slave 节点完成 task 的跟踪和执行。
- 具体执行逻辑上:
- 首先的输入文件,可以是多个已经拆分了的小文件,也可以是一个大文件
[……]阅读全文

