
java.util.concurrent 包的类都来自于 JSR-166:Concurrent Utilities,官方的描述叫做“The JSR proposes a set of medium-level utilities that provide functionality commonly needed in concurrent programs. ”。作者是大名鼎鼎的 Doug Lea,这个包的前身可以在这里找到,它最好的文档就是系统的 API 手册。
当然,这里参考的 concurrent 包来自 JDK7,比最初 JDK1.5 的版本有了不少改进。我曾经在 《Java 多线程发展简史》提到过,对于 Java 并发本身,在基础的并发模型建立以后,JSR-133 和 JSR-166 是贡献最大的两个,如觉必要,在阅读这篇文章之前,你可以先移步阅读这篇文章,能帮助在脑子里建立起最基础的 Java 多线程知识模型;此外,还有一篇是 《从 DCL 的对象安全发布谈起》,这篇文章相当于是对 JSR-133 规范的阅读理解。
这篇文章中,我只是简要地记录类的功能和使用,希望可以帮助大家全面掌握或回顾 Java 的并发包。当然,任何不清楚的接口和功能,JDK 的 API 手册是最好的参考材料,如果想更进一步,参透至少大部分类的实现代码,这会非常非常辛苦。
并发容器
这些容器的关键方法大部分都实现了线程安全的功能,却不使用同步关键字 (synchronized)。值得注意的是 Queue 接口本身定义的几个常用方法的区别,
- add 方法和 offer 方法的区别在于超出容量限制时前者抛出异常,后者返回 false;
- remove 方法和 poll 方法都从队列中拿掉元素并返回,但是他们的区别在于空队列下操作前者抛出异常,而后者返回 null;
- element 方法和 peek 方法都返回队列顶端的元素,但是不把元素从队列中删掉,区别在于前者在空队列的时候抛出异常,后者返回 null。
阻塞队列:
- BlockingQueue.class,阻塞队列接口
- BlockingDeque.class,双端阻塞队列接口
- ArrayBlockingQueue.class,阻塞队列,数组实现
- LinkedBlockingDeque.class,阻塞双端队列,链表实现
- LinkedBlockingQueue.class,阻塞队列,链表实现
- DelayQueue.class,阻塞队列,并且元素是 Delay 的子类,保证元素在达到一定时间后才可以取得到
- PriorityBlockingQueue.class,优先级阻塞队列
- SynchronousQueue.class,同步队列,但是队列长度为 0,生产者放入队列的操作会被阻塞,直到消费者过来取,所以这个队列根本不需要空间存放元素;有点像一个独木桥,一次只能一人通过,还不能在桥上停留
非阻塞队列:
- ConcurrentLinkedDeque.class,非阻塞双端队列,链表实现
- ConcurrentLinkedQueue.class,非阻塞队列,链表实现
转移队列:
- TransferQueue.class,转移队列接口,生产者要等消费者消费的队列,生产者尝试把元素直接转移给消费者
- LinkedTransferQueue.class,转移队列的链表实现,它比 SynchronousQueue 更快
其它容器:
- ConcurrentMap.class,并发 Map 的接口,定义了 putIfAbsent(k,v)、remove(k,v)、replace(k,oldV,newV)、replace(k,v) 这四个并发场景下特定的方法
- ConcurrentHashMap.class,并发 HashMap
- ConcurrentNavigableMap.class,NavigableMap 的实现类,返回最接近的一个元素
- ConcurrentSkipListMap.class,它也是 NavigableMap 的实现类(要求元素之间可以比较),同时它比 ConcurrentHashMap 更加 scalable——ConcurrentHashMap 并不保证它的操作时间,并且你可以自己来调整它的 load factor;但是 ConcurrentSkipListMap 可以保证 O(log n) 的性能,同时不能自己来调整它的并发参数,只有你确实需要快速的遍历操作,并且可以承受额外的插入开销的时候,才去使用它
- ConcurrentSkipListSet.class,和上面类似,只不过 map 变成了 set
- CopyOnWriteArrayList.class,copy-on-write 模式的 array list,每当需要插入元素,不在原 list 上操作,而是会新建立一个 list,适合读远远大于写并且写时间并苛刻的场景
- CopyOnWriteArraySet.class,和上面类似,list 变成 set 而已
同步设备
这些类大部分都是帮助做线程之间同步的,简单描述,就像是提供了一个篱笆,线程执行到这个篱笆的时候都得等一等,等到条件满足以后再往后走。
- CountDownLatch.class,一个线程调用 await 方法以后,会阻塞地等待计数器被调用 countDown 直到变成 0,功能上和下面的 CyclicBarrier 有点像
- CyclicBarrier.class,也是计数等待,只不过它是利用 await 方法本身来实现计数器“+1” 的操作,一旦计数器上显示的数字达到 Barrier 可以打破的界限,就会抛出 BrokenBarrierException,线程就可以继续往下执行;请参见我写过的这篇文章 《同步、异步转化和任务执行》中的 Barrier 模式
- Semaphore.class,功能上很简单,acquire() 和 release() 两个方法,一个尝试获取许可,一个释放许可,Semaphore 构造方法提供了传入一个表示该信号量所具备的许可数量。
- Exchanger.class,这个类的实例就像是两列飞驰的火车(线程)之间开了一个神奇的小窗口,通过小窗口(exchange 方法)可以让两列火车安全地交换数据。
- Phaser.class,功能上和第 1、2 个差不多,但是可以重用,且更加灵活,稍微有点复杂(CountDownLatch 是不断-1,CyclicBarrier 是不断+1,而 Phaser 定义了两个概念,phase 和 party),我在下面画了张图,希望能够帮助理解:
- 一个是 phase,表示当前在哪一个阶段,每碰到一次 barrier 就会触发 advance 操作(触发前调用 onAdvance 方法),一旦越过这道 barrier 就会触发 phase+1,这很容易理解;
- 另一个是 party,很多文章说它就是线程数,但是其实这并不准确,它更像一个用于判断 advance 是否被允许发生的计数器:
- 任何时候都有一个 party 的总数,即注册(registered)的 party 数,它可以在 Phaser 构造器里指定,也可以任意时刻调用方法动态增减;
- 每一个 party 都有 unarrived 和 arrived 两种状态,可以通过调用 arriveXXX 方法使得它从 unarrived 变成 arrived;
- 每一个线程到达 barrier 后会等待(调用 arriveAndAwaitAdvance 方法),一旦所有 party 都到达(即 arrived 的 party 数量等于 registered 的数量),就会触发 advance 操作,同时 barrier 被打破,线程继续向下执行,party 重新变为 unarrived 状态,重新等待所有 party 的到达;
- 在绝大多数情况下一个线程就只负责操控一个 party 的到达,因此很多文章说 party 指的就是线程,但是这是不准确的,因为一个线程完全可以操控多个 party,只要它执行多次的 arrive 方法。
- 结合 JDK 的文档如果还无法理解,请参看这篇博客(墙外),它说得非常清楚;之后关于它的几种典型用法请参见这篇文章。

给出一个 Phaser 使用的最简单的例子:
public class T {
public static void main(String args[]) {
final int count = 3;
final Phaser phaser = new Phaser(count); // 总共有 3 个 registered parties
for(int i = 0; i < count; i++) {
final Thread thread = new Thread(new Task(phaser));
thread.start();
}
}
public static class Task implements Runnable {
private final Phaser phaser;
public Task(Phaser phaser) {
this.phaser = phaser;
}
@Override
public void run() {
phaser.arriveAndAwaitAdvance(); // 每执行到这里,都会有一个 party arrive,如果 arrived parties 等于 registered parties,就往下继续执行,否则等待
}
}
}
原子对象
这些对象都的行为在不使用同步的情况下保证了原子性。值得一提的有两点:
- weakCompareAndSet 方法:compareAndSet 方法很明确,但是这个是啥?根据 JSR 规范,调用 weakCompareAndSet 时并不能保证 happen-before 的一致性,因此允许存在重排序指令等等虚拟机优化导致这个操作失败(较弱的原子更新操作),但是从 Java 源代码看,它的实现其实和 compareAndSet 是一模一样的;
- lazySet 方法:延时设置变量值,这个等价于 set 方法,但是由于字段是 volatile 类型的,因此次字段的修改会比普通字段(非 volatile 字段)有稍微的性能损耗,所以如果不需要立即读取设置的新值,那么此方法就很有用。
- AtomicBoolean.class
- AtomicInteger.class
- AtomicIntegerArray.class
- AtomicIntegerFieldUpdater.class
- AtomicLong.class
- AtomicLongArray.class
- AtomicLongFieldUpdater.class
- AtomicMarkableReference.class,它是用来高效表述 Object-boolean 这样的对象标志位数据结构的,一个对象引用+一个 bit 标志位
- AtomicReference.class
- AtomicReferenceArray.class
- AtomicReferenceFieldUpdater.class
- AtomicStampedReference.class,它和前面的 AtomicMarkableReference 类似,但是它是用来高效表述 Object-int 这样的“ 对象+版本号” 数据结构,特别用于解决 ABA 问题(ABA 问题这篇文章里面也有介绍)
锁
- AbstractOwnableSynchronizer.class,这三个 AbstractXXXSynchronizer 都是为了创建锁和相关的同步器而提供的基础,锁,还有前面提到的同步设备都借用了它们的实现逻辑
- AbstractQueuedLongSynchronizer.class,AbstractOwnableSynchronizer 的子类,所有的同步状态都是用 long 变量来维护的,而不是 int,在需要 64 位的属性来表示状态的时候会很有用
- AbstractQueuedSynchronizer.class,为实现依赖于先进先出队列的阻塞锁和相关同步器(信号量、事件等等)提供的一个框架,它依靠 int 值来表示状态
- Lock.class,Lock 比 synchronized 关键字更灵活,而且在吞吐量大的时候效率更高,根据 JSR-133 的定义,它 happens-before 的语义和 synchronized 关键字效果是一模一样的,它唯一的缺点似乎是缺乏了从 lock 到 finally 块中 unlock 这样容易遗漏的固定使用搭配的约束,除了 lock 和 unlock 方法以外,还有这样两个值得注意的方法:
- lockInterruptibly:如果当前线程没有被中断,就获取锁;否则抛出 InterruptedException,并且清除中断
- tryLock,只在锁空闲的时候才获取这个锁,否则返回 false,所以它不会 block 代码的执行
- ReadWriteLock.class,读写锁,读写分开,读锁是共享锁,写锁是独占锁;对于读-写都要保证严格的实时性和同步性的情况,并且读频率远远大过写,使用读写锁会比普通互斥锁有更好的性能。
- ReentrantLock.class,可重入锁(lock 行为可以嵌套,但是需要和 unlock 行为一一对应),有几点需要注意:
- 构造器支持传入一个表示是否是公平锁的 boolean 参数,公平锁保证一个阻塞的线程最终能够获得锁,因为是有序的,所以总是可以按照请求的顺序获得锁;不公平锁意味着后请求锁的线程可能在其前面排列的休眠线程恢复前拿到锁,这样就有可能提高并发的性能
- 还提供了一些监视锁状态的方法,比如 isFair、isLocked、hasWaiters、getQueueLength 等等
- ReentrantReadWriteLock.class,可重入读写锁
- Condition.class,使用锁的 newCondition 方法可以返回一个该锁的 Condition 对象,如果说锁对象是取代和增强了 synchronized 关键字的功能的话,那么 Condition 则是对象 wait/notify/notifyAll 方法的替代。在下面这个例子中,lock 生成了两个 condition,一个表示不满,一个表示不空:
- 在 put 方法调用的时候,需要检查数组是不是已经满了,满了的话就得等待,直到“ 不满” 这个 condition 被唤醒(notFull.await());
- 在 take 方法调用的时候,需要检查数组是不是已经空了,如果空了就得等待,直到“ 不空” 这个 condition 被唤醒(notEmpty.await()):
class BoundedBuffer {
final Lock lock = new ReentrantLock();
final Condition notFull = lock.newCondition();
final Condition notEmpty = lock.newCondition();
final Object[] items = new Object[100];
int putptr, takeptr, count;
public void put(Object x) throws InterruptedException {
lock.lock();
try {
while (count == items.length)
notFull.await();
items[putptr] = x;
if (++putptr == items.length) putptr = 0;
++count;
notEmpty.signal(); // 既然已经放进了元素,肯定不空了,唤醒“notEmpty”
} finally {
lock.unlock();
}
}
public Object take() throws InterruptedException {
lock.lock();
try {
while (count == 0)
notEmpty.await();
Object x = items[takeptr];
if (++takeptr == items.length) takeptr = 0;
--count;
notFull.signal(); // 既然已经拿走了元素,肯定不满了,唤醒“notFull”
return x;
} finally {
lock.unlock();
}
}
}
Fork-join 框架
这是一个 JDK7 引入的并行框架,它把流程划分成 fork(分解)+join(合并)两个步骤(怎么那么像 MapReduce?),传统线程池来实现一个并行任务的时候,经常需要花费大量的时间去等待其他线程执行任务的完成,但是 fork-join 框架使用 work stealing 技术缓解了这个问题:
- 每个工作线程都有一个双端队列,当分给每个任务一个线程去执行的时候,这个任务会放到这个队列的头部;
- 当这个任务执行完毕,需要和另外一个任务的结果执行合并操作,可是那个任务却没有执行的时候,不会干等,而是把另一个任务放到队列的头部去,让它尽快执行;
- 当工作线程的队列为空,它会尝试从其他线程的队列尾部偷一个任务过来;
- 取得的任务可以被进一步分解。
- ForkJoinPool.class,ForkJoin 框架的任务池,ExecutorService 的实现类
- ForkJoinTask.class,Future 的子类,框架任务的抽象
- ForkJoinWorkerThread.class,工作线程
- RecursiveTask.class,ForkJoinTask 的实现类,compute 方法有返回值,下文中有例子
- RecursiveAction.class,ForkJoinTask 的实现类,compute 方法无返回值,只需要覆写 compute 方法,对于可继续分解的子任务,调用 coInvoke 方法完成(参数是 RecursiveAction 子类对象的可变数组):
class SortTask extends RecursiveAction {
final long[] array;
final int lo;
final int hi;
private int THRESHOLD = 30;
public SortTask(long[] array) {
this.array = array;
this.lo = 0;
this.hi = array.length - 1;
}
public SortTask(long[] array, int lo, int hi) {
this.array = array;
this.lo = lo;
this.hi = hi;
}
@Override
protected void compute() {
if (hi - lo < THRESHOLD)
sequentiallySort(array, lo, hi);
else {
int pivot = partition(array, lo, hi);
coInvoke(new SortTask(array, lo, pivot - 1), new SortTask(array,
pivot + 1, hi));
}
}
private int partition(long[] array, int lo, int hi) {
long x = array[hi];
int i = lo - 1;
for (int j = lo; j < hi; j++) {
if (array[j] <= x) {
i++;
swap(array, i, j);
}
}
swap(array, i + 1, hi);
return i + 1;
}
private void swap(long[] array, int i, int j) {
if (i != j) {
long temp = array[i];
array[i] = array[j];
array[j] = temp;
}
}
private void sequentiallySort(long[] array, int lo, int hi) {
Arrays.sort(array, lo, hi + 1);
}
}
测试的调用代码:
@Test
public void testSort() throws Exception {
ForkJoinTask sort = new SortTask(array);
ForkJoinPool fjpool = new ForkJoinPool();
fjpool.submit(sort);
fjpool.shutdown();
fjpool.awaitTermination(30, TimeUnit.SECONDS);
assertTrue(checkSorted(array));
}
RecursiveTask 和 RecursiveAction 的区别在于它的 compute 是可以有返回值的,子任务的计算使用 fork() 方法,结果的获取使用 join() 方法:
class Fibonacci extends RecursiveTask {
final int n;
Fibonacci(int n) {
this.n = n;
}
private int compute(int small) {
final int[] results = { 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89 };
return results[small];
}
public Integer compute() {
if (n <= 10) {
return compute(n);
}
Fibonacci f1 = new Fibonacci(n - 1);
Fibonacci f2 = new Fibonacci(n - 2);
f1.fork();
f2.fork();
return f1.join() + f2.join();
}
}
执行器和线程池
这个是我曾经举过的例子:
public class FutureUsage {
public static void main(String[] args) {
ExecutorService executor = Executors.newSingleThreadExecutor();
Callable<Object> task = new Callable<Object>() {
public Object call() throws Exception {
Thread.sleep(4000);
Object result = "finished";
return result;
}
};
Future<Object> future = executor.submit(task);
System.out.println("task submitted");
try {
System.out.println(future.get());
} catch (InterruptedException e) {
} catch (ExecutionException e) {
}
// Thread won't be destroyed.
}
}
线程池具备这样的优先级处理策略:
- 请求到来首先交给 coreSize 内的常驻线程执行
- 如果 coreSize 的线程全忙,任务被放到队列里面
- 如果队列放满了,会新增线程,直到达到 maxSize
- 如果还是处理不过来,会把一个异常扔到 RejectedExecutionHandler 中去,用户可以自己设定这种情况下的最终处理策略
对于大于 coreSize 而小于 maxSize 的那些线程,空闲了 keepAliveTime 后,会被销毁。观察上面说的优先级顺序可以看到,假如说给 ExecutorService 一个无限长的队列,比如 LinkedBlockingQueue,那么 maxSize>coreSize 就是没有意义的。
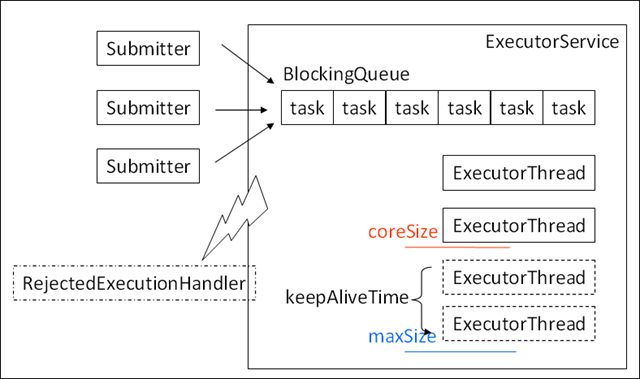
ExecutorService:
- Future.class,异步计算的结果对象,get 方法会阻塞线程直至真正的结果返回
- Callable.class,用于异步执行的可执行对象,call 方法有返回值,它和 Runnable 接口很像,都提供了在其他线程中执行的方法,二者的区别在于:
- Runnable 没有返回值,Callable 有
- Callable 的 call 方法声明了异常抛出,而 Runnable 没有
- RunnableFuture.class,实现自 Runnable 和 Future 的子接口,成功执行 run 方法可以完成它自身这个 Future 并允许访问其结果,它把任务执行和结果对象放到一起了
- FutureTask.class,RunnableFuture 的实现类,可取消的异步计算任务,仅在计算完成时才能获取结果,一旦计算完成,就不能再重新开始或取消计算;它的取消任务方法 cancel(boolean mayInterruptIfRunning) 接收一个 boolean 参数表示在取消的过程中是否需要设置中断
- Executor.class,执行提交任务的对象,只有一个 execute 方法
- Executors.class,辅助类和工厂类,帮助生成下面这些 ExecutorService
- ExecutorService.class,Executor 的子接口,管理执行异步任务的执行器,AbstractExecutorService 提供了默认实现
- AbstractExecutorService.class,ExecutorService 的实现类,提供执行方法的默认实现,包括:
- ① submit 的几个重载方法,返回 Future 对象,接收 Runnable 或者 Callable 参数
- ② invokeXXX 方法,这类方法返回的时候,任务都已结束,即要么全部的入参 task 都执行完了,要么 cancel 了
- ThreadPoolExecutor.class,线程池,AbstractExecutorService 的子类,除了从 AbstractExecutorService 继承下来的①、②两类提交任务执行的方法以外,还有:
- ③ 实现自 Executor 接口的 execute 方法,接收一个 Runnable 参数,没有返回值
- RejectedExecutionHandler.class,当任务无法被执行的时候,定义处理逻辑的地方,前面已经提到过了
- ThreadFactory.class,线程工厂,用于创建线程
- Delayed.class,延迟执行的接口,只有 long getDelay(TimeUnit unit) 这样一个接口方法
- ScheduledFuture.class,Delayed 和 Future 的共同子接口
- RunnableScheduledFuture.class,ScheduledFuture 和 RunnableFuture 的共同子接口,增加了一个方法 boolean isPeriodic(),返回它是否是一个周期性任务,一个周期性任务的特点在于它可以反复执行
- ScheduledExecutorService.class,ExecutorService 的子接口,它允许任务延迟执行,相应地,它返回 ScheduledFuture
- ScheduledThreadPoolExecutor.class,可以延迟执行任务的线程池
CompletionService:
- CompletionService.class,它是对 ExecutorService 的改进,因为 ExecutorService 只是负责处理任务并把每个任务的结果对象(Future)给你,却并没有说要帮你“ 管理” 这些结果对象,这就意味着你得自己建立一个对象容器存放这些结果对象,很麻烦;CompletionService 像是集成了一个 Queue 的功能,你可以调用 Queue 一样的方法——poll 来获取结果对象,还有一个方法是 take,它和 poll 差不多,区别在于 take 方法在没有结果对象的时候会返回空,而 poll 方法会 block 住线程直到有结果对象返回
- ExecutorCompletionService.class,是 CompletionService 的实现类
其它:
- ThreadLocalRandom.class,随机数生成器,它和 Random 类差不多,但是它的性能要高得多,因为它的种子内部生成后,就不再修改,而且随机对象不共享,就会减少很多消耗和争用,由于种子内部生成,因此生成随机数的方法略有不同:
ThreadLocalRandom.current().nextX(…)
文章未经特殊标明皆为本人原创,未经许可不得用于任何商业用途,转载请保持完整性并注明来源链接 《四火的唠叨》
四火兄总结的太好了!受益良多,非常感谢!
最近在通过《Java 并发编程》来学习并发编程,过程中经常参考你这篇文章,互相对照互为补充。